About ingestion#
Ingestion process#
EclecticIQ Intelligence Center can ingest data in different formats from multiple sources.
Data ingestion is a multi-step process:
Incoming data flows in, and it is added to the ingestion queue.
Packages are fetched from the ingestion queue to be processed.
Packages are processed, and data is:
Deduplicated
Normalized
Transformed to EclecticIQ Intelligence Center’s internal data model:
Entities
Observables
Relationships
Rules and filters further treat the data to:
Enrich entities
Create relationships
Apply tags to entities
Save entities and observables to specific datasets
Assign a maliciousness confidence level to observables.
EclecticIQ Intelligence Center attempts to resolve ID references (
idref) by checking if the actual data IDs point to is available.Ingested entities and observables are stored to the databases (main data store, search database, and graph database), and they are searchable and available in the Intelligence Center.
Deduplication#
Data deduplication sifts through ingested data to check if it already exists in EclecticIQ Intelligence Center.
It avoids cluttering the databases with unnecessary copies of the same data.
EclecticIQ Intelligence Center deduplicates data at package, entity, and observable level.
When checking newly ingested packages vs. existing ones, package-level deduplication compares the former with the latter.
If an ingested package is a copy of an existing one; that is, both packages have the same hash value:
The ingested duplicate package is discarded.
Existing entities from the existing package are updated as for their source information to include the origin of the duplicate package as an additional data source.
When checking newly ingested entities vs. existing ones, entity-level deduplication handles the following scenarios:
Same STIX ID, same data: merged to one entity
Multiple entities with identical STIX ID AND identical content are handled like identical copies.
Identical copies of the same entity are merged to one entity.
Before deduplication
After deduplication
Multiple entities
Same STIX ID
Same data content (Identical copies)
Identical copies are merged to one entity.
Same STIX ID, slightly different data, different timestamps: entity update and new version
Multiple entities with identical STIX ID AND slightly different content are handled like minor revisions of the same entity.
In this case, slightly different content means different timestamps and minor differences in the entity content.
For example, a minor revision update reference, or a small edit such as fixing a typo in the title, description, or another similar field.
The existing entity is updated with the most recent content.
As a result of the entity update, a new version of the entity is created.
Before deduplication
After deduplication
Multiple entities
Same STIX ID
Different timestamps
Slightly different content
(Minor revisions of the same entity; not different versions of the same entity)
The existing entity is updated with the content from the entity variant with the most recent timestamp.
The process produces a new version of the entity.
Same STIX ID, same data, different timestamps: timestamp update, no new version
Multiple entities with identical STIX ID AND identical content BUT different timestamps are handled like chronological copies of the same entity.
The timestamp of the existing entity is updated to the most recent value, without creating a new version of the entity.
Before deduplication
After deduplication
Multiple entities
Same STIX ID
Different timestamps
(Chronological copies of the same entity)
Same data content
The existing entity timestamp value is updated to the most recent one.
Updating only the timestamp and leaving all other data unchanged does not trigger producing a new version of the entity.
Note
If you upload an entity by sending a POST request
to the /private/entities/ API endpoint,
entity deduplication relies on the entity data hash,
instead of the entity STIX ID.
In this case, EclecticIQ Intelligence Center checks if the hash value of the uploaded entity already exists.
It does not compare the entity.data["id"] value of the
uploaded entity to check if it matches the
data.id field value of an existing entity.
Entity resolution#
An entity is resolved when its
idrefmatches existing, available data in EclecticIQ Intelligence Center.An entity is unresolved when its
idrefdoes not match any existing data in EclecticIQ Intelligence Center.
idref resolution at entity level#
Entities and observables can reference external
data through the STIX and CybOX idref
field.
When the idref
is at entity level — that is, when the
entity has a STIX ID — EclecticIQ Intelligence Center creates an
entity relationship between the entities.
When a STIX idref references an entity, the Intelligence Center creates a direct relationship to associate the two entities.
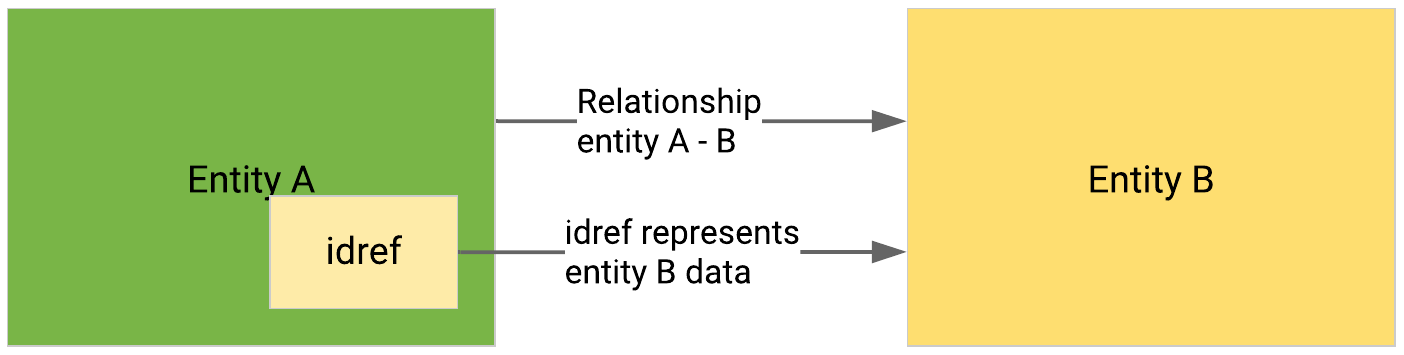
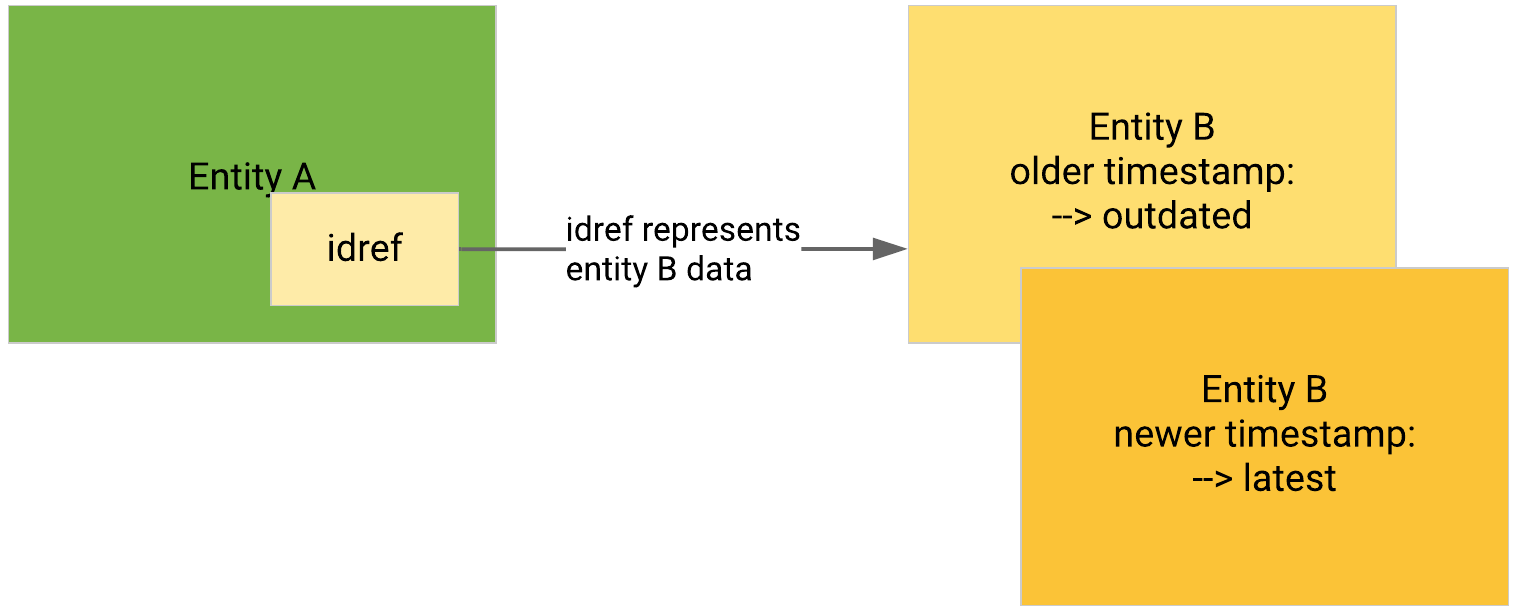
When a STIX
idrefreferences an entity of the same type and content as the entity it belongs to, and where the only differences are either thetimestamp, or the version reference values between the two entities, the Intelligence Center marks all but the latest version of the entity update chain as outdated.Outdated entities have historical reference; they are not searchable.
idref resolution at nested object level#
When the idref -> id reference is at nested object level
– that is, when an entity includes either a referenced
entity, or a bundled observable/an embedded CybOX observable
with an idref
– EclecticIQ Intelligence Center attempts to
resolve the bundled object idref
by looking for the
referenced data:
If the bundled object
idrefreferences data available inside the same ingested package, or data stored in EclecticIQ Intelligence Center, the newly ingestedidrefis removed and it is replaced with the existing referenced data.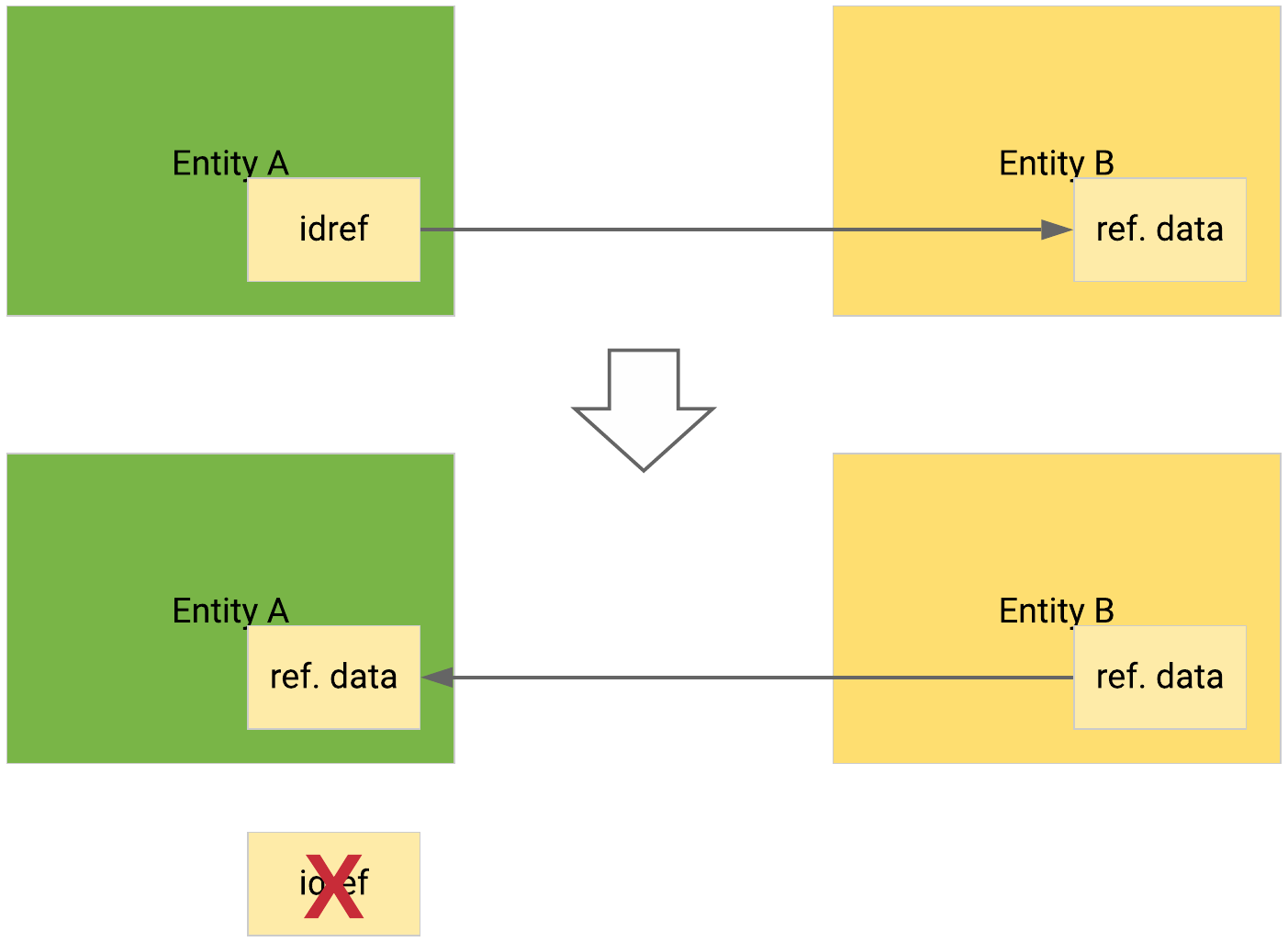
Referenced data is available, either inside the same ingested package, or in EclecticIQ Intelligence Center#
If the
idrefreferences unavailable data at the moment, the reference is resolved if/when the referenced data becomes available.idrefs pointing to unknown/unavailable data produce placeholder entities that are populated if and when actual data becomes available at a later time.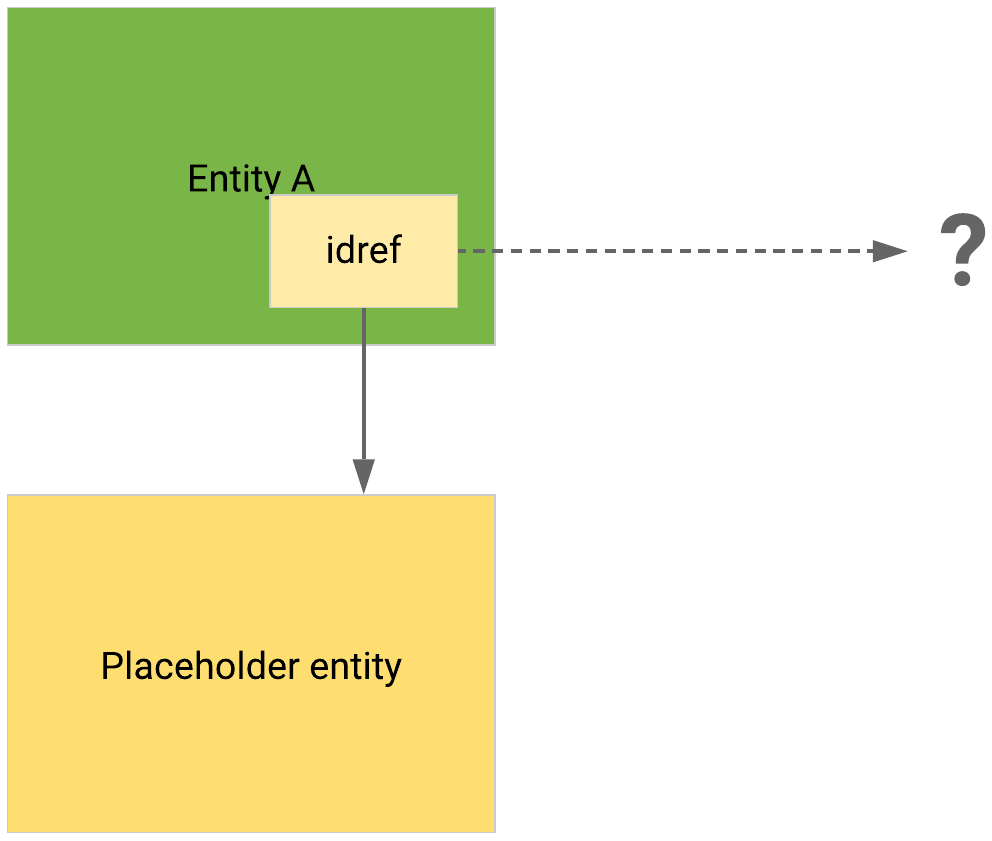
Referenced data is unavailable; a placeholder points to it, in case it becomes available in the future.#
The process works identically in the opposite direction: if
bundled entity or observable/CybOX data is ingested, the
Intelligence Center looks for an existing idref
pointing to it.
If it finds a matching
idref, the existingidrefis removed, and it is replaced with the newly ingested referenced data.If no matching
idrefis available, nothing happens.If a matching
idrefbecomes available at a later time, it will be resolved then by replacing it with the corresponding referenced data.
Refanging URIs#
Defanging defuses suspicious or harmful URLs. Although there are no set standards, several approaches to defanging have gained popularity over time, and are now widely used.
EclecticIQ Intelligence Center defangs URLs by recognizing common patterns in potentially malicious URLs.
During ingestion EclecticIQ Intelligence Center refangs defanged URIs:
URIs/URLs
IP addresses
Domain names
Email addresses.
Incoming data may contain defanged URIs and URLs to defuse them and to make them safe for dissemination.
Intelligence vendors and providers often defang malicious IPs and domains to prevent recipients from reaching those malicious resources by mistake.
During ingestion, EclecticIQ Intelligence Center looks for defanged URIs; when it detects them, it refangs them – that is, the URIs become dangerous again because they point to potentially existing harmful resources.
Refanged URIs are not clickable hyperlinks: for example, users need to manually copy and paste them into a web browser address bar to reach a malicious resource.
Refanging URIs is a preliminary step to data deduplication.
On ingestion, when EclecticIQ Intelligence Center detects duplicate data that replicate the same information about the same URIs, and when the only difference lies in the safe vs. malicious URI scheme, it refangs the safe URI scheme, and then it deduplicates the data.
Defanged |
Refanged |
Example |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Multiple data sources#
EclecticIQ Intelligence Center can ingest the same entity from more than one source.
While the entity data is deduplicated during ingestion, available information about the data sources the entity originates from is retained in a list of sources.
Multiple data sources for an entity are indexed, and they are searchable.
Multiple data source information for an entity is stored in the sources JSON field as an object array.
{
"sources": [
{
"name": "TAXII Stand Samples Cypress",
"source_id": "09d01570-476d-4515-a458-faddb43hse86",
"source_type": "incoming_feed"
},
{
"name": "test.taxiistand.com",
"source_id": "0bd6014d-e0b4-a8d5-83ac-c107fd034855",
"source_type": "incoming_feed"
},
{
"name": "TAXII Stand Samples",
"source_id": "fc602bf6-f653-1234-8dde-b939f2bb13bd",
"source_type": "incoming_feed"
}
]
}
When an entity has more than one data source, a counter is displayed next to the main entity data source name under the Source column.
Click it to view a tooltip with a list of all the data sources the entity refers to.
About data source changes#
Changes to data sources can trigger rules#
When EclecticIQ Intelligence Center ingests duplicate data, it updates existing entities to add the origin of the duplicate data as a new data source.
When changes to the data sources for an entity occur – for example, adding a new data source, renaming an enricher, or deleting an incoming feed – the process triggers entity and observable rules that use the changed data sources as a criterion:
The current data sources of the affected entities are reassessed.
For example, any unavailable sources, such as a deleted incoming feed, are dropped; new sources, such as the origin of a discarded duplicate package, are added.
The timestamp recording the most recent entity update is set to now; that is, the time the data source change occurs.
Entity and observable rules are triggered to update any entity information that may have changed because of the data source modification.
It is possible to manually rename enrichers.
However, changing the name of an enricher equals to reassigning enrichment observables to a different source.
This process drops the affected observables from the current source, it attaches them to the newly designated source, and it triggers a number of rules:
The current data source of the observable is dropped.
The new data source is attached.
The timestamp recording the most recent observable update is set to now – that is, the time the data source change is applied.
All entities in EclecticIQ Intelligence Center are re-indexed, as well as all observables whose data source has changed as a consequence of renaming the enricher they refer to.
Changes to data sources can trigger database reindexing#
Entity deletion and incoming feed purge actions trigger a database reindex process, because they involve dropping any data sources referring to the deleted incoming feed content and entities:
When you delete an entity, you also detach from the deleted entity any data sources referring to it.
When you delete or purge an incoming feed, you also remove it as a data source from the entities that refer to it.
Changes to data sources can affect user access#
Changes to entity data sources affect user access to entity data.
For example, if the data source an entity refers to changes from group A to group B, group A members who are not also members of group B can no longer access the entity.
About aggregate values#
Entities ingested from multiple sources can have different values for timestamp, source reliability, TLP, and half-life.
During ingestion, these values are aggregated based on value type to produce a resulting single value to assign to the ingested entities:
Timestamp
When processing multiple timestamps for an entity, the oldest one prevails – that is, the one indicating the earliest moment in time when the entity was ingested.
Source reliability
When processing multiple source reliability values for an entity, the highest one prevails – that is, the one representing the highest data source reliability level.
TLP
When processing multiple TLP values for an entity, the least restrictive TLP value prevails, and it is applied to the resulting ingested entity.
TLP overrides have precedence over the original entity TLP value.
TLP overrides always supersede the original TLP value assigned to an entity, regardless of the TLP override being more or less restrictive than the original TLP value.
Half-life
When processing multiple half-life values for an entity, the highest one prevails, and it is applied to the resulting ingested entity.
Processed half-life values always supersede the system-defined or the default half-life value for an entity.
Saving data#
Last but not least, the Intelliegence Center saves ingested entities, observables, enrichments, and any established relationships to the databases in the following order:
Main data store (PostgreSQL).
Indexing and search data store (Elasticsearch).
Graph data store (Neo4j).
Saving data URIs#
The extracted entity data that is stored inside observables ranges from short, simple data such as email addresses, domain names, IP addresses, and so on, to binary data.
When an entity contains binary data — for example, a file, a memory region, or packet capture (PCAP) data — the data can be represented as either a data URI or a CybOX raw artifact element.
During ingestion, extraction logic handles binary data URI and raw artifact objects embedded in CybOX objects in the following way:
data URIs are extracted and stored as entity attachments and new hash values:
The data URI value is recalculated to a new hash:
uri-hash-sha256.The SHA-256 hash value for
uri-hash-sha256is calculated over the UTF-8 encoding of the data URI string.The
uri-hash-sha256hash substitute enables entity correlation among entities containing the same data URI.
The binary data/raw content embedded in the data URI is decoded and processed:
The extracted content is hashed using SHA-512, SHA-256, SHA-1, and MD5.
Each resulting hash is added to the relevant entities as an observable.
Example
A data URI with image content nested inside a CybOX object generates the following output:
1
uri-hash-sha256hash to facilitate entity correlation.4 calculated hash observables:
hash-sha512,hash-sha256,hash-sha1, andhash-md5.
Failed packages#
Sometimes ingestion may fail to process a package.
Instead of immediately flagging the package as failed, the process automatically attempts to ingest the package again.
If the package still fails to ingest after a predefined amount of attempts, then EclecticIQ Intelligence Center flags it as failed.
The following parameters in the /etc/eclecticiq/ platform_settings.py configuration file define the behavior
of the mechanism that automatically retries to ingest failed
packages:
INGESTION_TASK_RETRY_SETTINGS = {
"max_attempts": 10,
"retry_delay": 60, # one minute
"max_retry_delay": 60 * 90, # 90 minutes
}
INGESTION_EXTERNAL_TASK_RETRY_SETTINGS = {
"max_attempts": 25,
"retry_delay": 60 * 5, # 5 minutes
"max_retry_delay": 60 * 60 * 12, # 12 hours
}
Attempts define how many times EclecticIQ Intelligence Center should try to ingest a package again, before flagging it as failed.
Delay parameters represent seconds.
They define the lower and upper boundaries used to calculate the retry interval between two consecutive attempts.
To attempt again to ingest a package that has been flagged as failed, you need to manually trigger reingestion.
Ingestion discrepancies#
Note
EclecticIQ JSON is the only supported format that enables sending entities, observables, enrichments, and source information from a source Intelligence Center instance to a recipient Intelligence Center instance.
To exchange data across Intelligence Center instances:
In the data source Intelligence Center instance set the outgoing feed content type to EclecticIQ JSON.
In the data destination Intelligence Center instance set the incoming feed content type to EclecticIQ JSON.
Fewer entities in target Intelligence Center#
When you exchange entity data between two Intelligence Center instances, and if the source data is in a format other than EclecticIQ JSON, an entity count discrepancy between the source and the destination Intelligence Centers may arise at the end of the operation.
This is expected behavior.
For example, let’s assume the source data format is STIX:
STIX and JSON are different formats.
STIX is much more nested than JSON, which has a flatter structure.
STIX entities are bundled in packages; after ingestion, the package is not needed any longer.
The ingestion process needs to parse the source data before ingesting it:
During parsing, STIX relationships between the package and the entities it contains are discarded, as they hold no intel value.
If the source package contains unresolved entities or observables whose idref is resolved during the parsing and ingestion steps, the original unresolved objects are discarded, as they hold no intel value because they are now resolved inside EclecticIQ Intelligence Center.
Relationships between entities or between entities and observables are retained and ingested into the Intelligence Center.
What looks like a discrepancy is the result of a data optimization and normalization process whose purpose is to separate the wheat from the chaff to retain only data with actual intelligence value.
Entity count mismatch#
When you add a batch of entities to a dataset, the GUI may display different entity counts in the dataset view and in the Add [n] entities to a dataset dialog window.
This UI inconsistency can impact all supported entity types.
A possible cause for the count mismatch can be malformed
STIX input, particularly malformed idref
that can
point to existing data — these idref
are resolved when
EclecticIQ Intelligence Center replaces them with the matching data
— or to data that is not yet available in the Intelligence
Center — these idref
remain unresolved as long as
there is no matching data to replace them with.
The count inconsistency is at GUI level only, and it can occur in the following scenario:
New data is being written to EclecticIQ Intelligence Center, AND
A user is examining the database view counter and the Add [n] entities to a dataset dialog window counter at the same time; that is, both GUI counters are displayed at the same time.