Release notes 2.7.1
|
Product |
EclecticIQ Platform |
|
Release version |
2.7.1 |
|
Release date |
13 May 2020 |
|
Summary |
Maintenance release |
|
Upgrade impact |
Medium |
|
Time to upgrade |
~5 minutes to upgrade
|
|
Time to migrate |
|
EclecticIQ Platform 2.7.1 is a a maintenance release. It contains a mix of fixes for bugs and minor improvements.
For more information about enhancements and improvements, see What's changed below.
For more information about bugs we fixed, see Important bug fixes below.
For more information about security issues we addressed, see Security issues and mitigation actions below.
This release does not introduce any major changes in features and functionality.
The reference product documentation for this release is the one describing EclecticIQ Platform 2.7.0.
Download
Follow the links below to download installable packages for EclecticIQ Platform 2.7.1 and its dependencies.
For more information about setting up repositories, refer to the installation documentation for your target operating system.
|
EclecticIQ Platform and dependencies |
|
|
EclecticIQ Platform extensions |
Upgrade
Upgrade paths from release 2.0.x(.x) to 2.7.1:
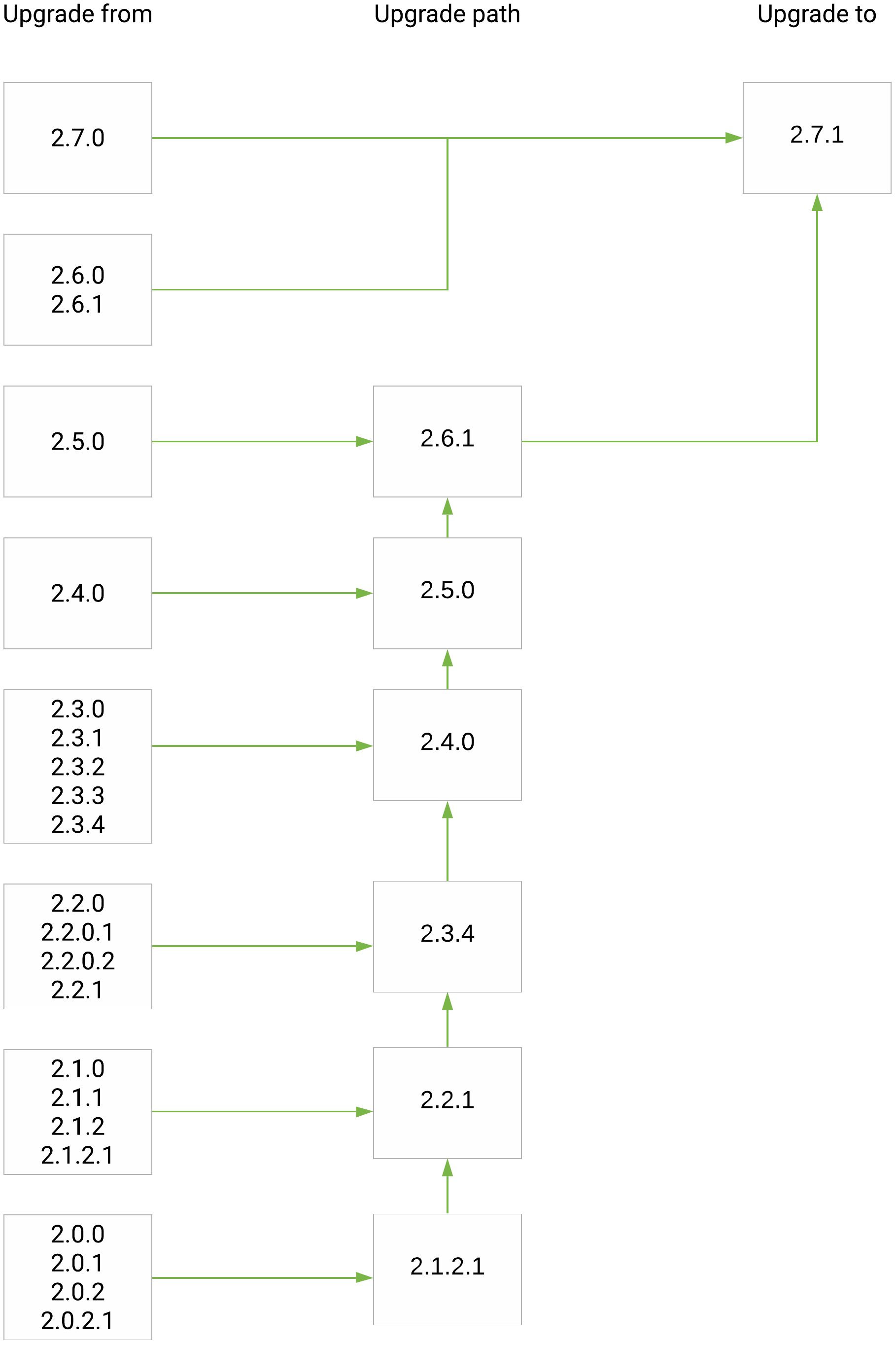
EclecticIQ Platform upgrade paths to release 2.7.1
After upgrading to this release, migrate the databases.
For more information, see the platform upgrade documentation for the OS in use:
|
CentOS |
RHEL |
Ubuntu |
What's changed
Improvements
eiq-platform search sync-data command
Command execution was slow, and performance would degrade with large volumes of data.
The execution of this command is now much faster, and performance has improved considerably also when running the command on large amounts of data.
Important bug fixes
This section is not an exhaustive list of all the important bug fixes we shipped with this release.
In previous releases, filter selection criteria beginning with raw. were not being applied properly on ingestion.
As a result, data points whose JSON paths began with raw. were being ignored.
The filter now works as documented in the online help article About criteria for entity rules.In previous releases, there was lag between the time entities were tagged and the time their last_updated_at field was updated.
As a result, some tagged entities were incorrectly excluded from earlier outgoing feeds although they were eventually included in later feeds.
Tagging entities and updating their last_updated_at now occur simultaneously so this problem no longer occurs.In previous releases, trying to save a graph to which observables from a Crowdstrike feed would fail.
This was due to two new fields that were not passing the platform's schema validation.
This problem has now been fixed.
Known issues
When more than 1000 entities are loaded on the graph, it is not possible to load related entities and observables by right-clicking an entity on the graph, and then by selecting Load entities, Load observables, or Load entities by observable.
In case of an ingestion process crash while ingestion is still ongoing, data is not synced to Elasticsearch.
MISP content ingestion through incoming feeds can be slow down and proceed slowly.
Between consecutive outgoing feed tasks, the platform may increase resource usage. This may result in an excessive memory consumption over time.
When an enricher reaches its monthly execution cap because it exceeds the allowed maximum number of requests, it fails, and it stops without returning a helpful error message.
Together with rate limiting, execution cap helps control data traffic for the enricher; for example, when the API or the service you are connecting to enforces usage limits.In the scenario where a dynamic datasets groups entities based on their tags, and the dynamic dataset view is open in a browser tab; if you add or remove entities to the dynamic dataset by changing their tag values while the dynamic dataset view is open in the browser tab, the view does not automatically update to reflect the changed dynamic dataset content.
To update the dynamic dataset view, you need to manually refresh the browser tab.If you open a draft entity detail pane, and then if you delete the draft entity while its detail pane is still open, the detail pane does not close automatically, and it displays an error message.
Systemd splits log lines exceeding 2048 characters into 2 or more lines.
As a result, log lines exceeding 2048 characters become invalid JSON, and Logstash is unable to parse them.
Security issues and mitigation actions
The following table lists known security issues, their severity, and the corresponding mitigation actions.
The state of an issue indicates whether a bug is still open, or if it was fixed in this release.
For more information, see All security issues and mitigation actions for a complete and up-to-date overview of open and fixed security issues.
|
ID |
CVE |
Description |
Severity |
Status |
Affected versions |
|
- |
Users with read-only permissions can delete objects from datasets |
1 - LOW |
|
2.7.1 and earlier. |
|
|
- |
Access to data sources through rules |
2 - MEDIUM |
Planned |
2.1.0 to 2.7.1 included. |
|
|
- |
Cross-site request forgery (CSRF) enables changes to Kibana |
1 - LOW |
Planned |
2.7.1 and earlier. |
Contact
For any questions, and to share your feedback about the documentation, contact us at [email protected] .