Release notes 2.7.0
|
Product |
EclecticIQ Platform |
|
Release version |
2.7.0 |
|
Release date |
08 Apr 2020 |
|
Summary |
Minor release |
|
Upgrade impact |
Medium |
|
Time to upgrade |
~5 minutes to upgrade
|
|
Time to migrate |
|
EclecticIQ Platform 2.7.0 is a minor release. It contains new features, improvements to existing functionality, as well as bug fixes.
Release 2.7.0 does not serve a single purpose like the previous minor release did. It rather pushes the Platform forward in ways that benefit both analysts during their investigations, and system admins in charge with keeping it running smoothly, compliant and secure.
Analysts can once again enjoy new features for the graph and search engine, speeding up their daily operations even further and improving the overall analyst experience. Together with the changes from the previous minor release, these new features mark a big step towards a more interactive graph and a more user-friendly search engine.
This time we have also worked on the Platform’s data management capability. Most notably, improvements have been made to the ingestion engine to prevent pipeline clogging. This has immediate impact for some customers, but also kicks-off a series of releases that will upgrade the ingestion engine in the long run.
Finally, release 2.7.0 also brings further improvements to the base functions of the Platform that allow customers to securely scale-up usage.
Follow the link and check out the new quick tour video from the team for a short rundown of these highlights.
For more information about new features and functionality, see What's new below.
For more information about enhancements and improvements, see What's changed below.
For more information about bugs we fixed, see Important bug fixes below.
For more information about security issues we addressed, see Security issues and mitigation actions below.
Download
Follow the links below to download installable packages for EclecticIQ Platform 2.7.0 and its dependencies.
For more information about setting up repositories, refer to the installation documentation for your target operating system.
|
EclecticIQ Platform and dependencies |
|
|
EclecticIQ Platform extensions |
Upgrade
Upgrade paths from release 2.0.x(.x) to 2.7.0:
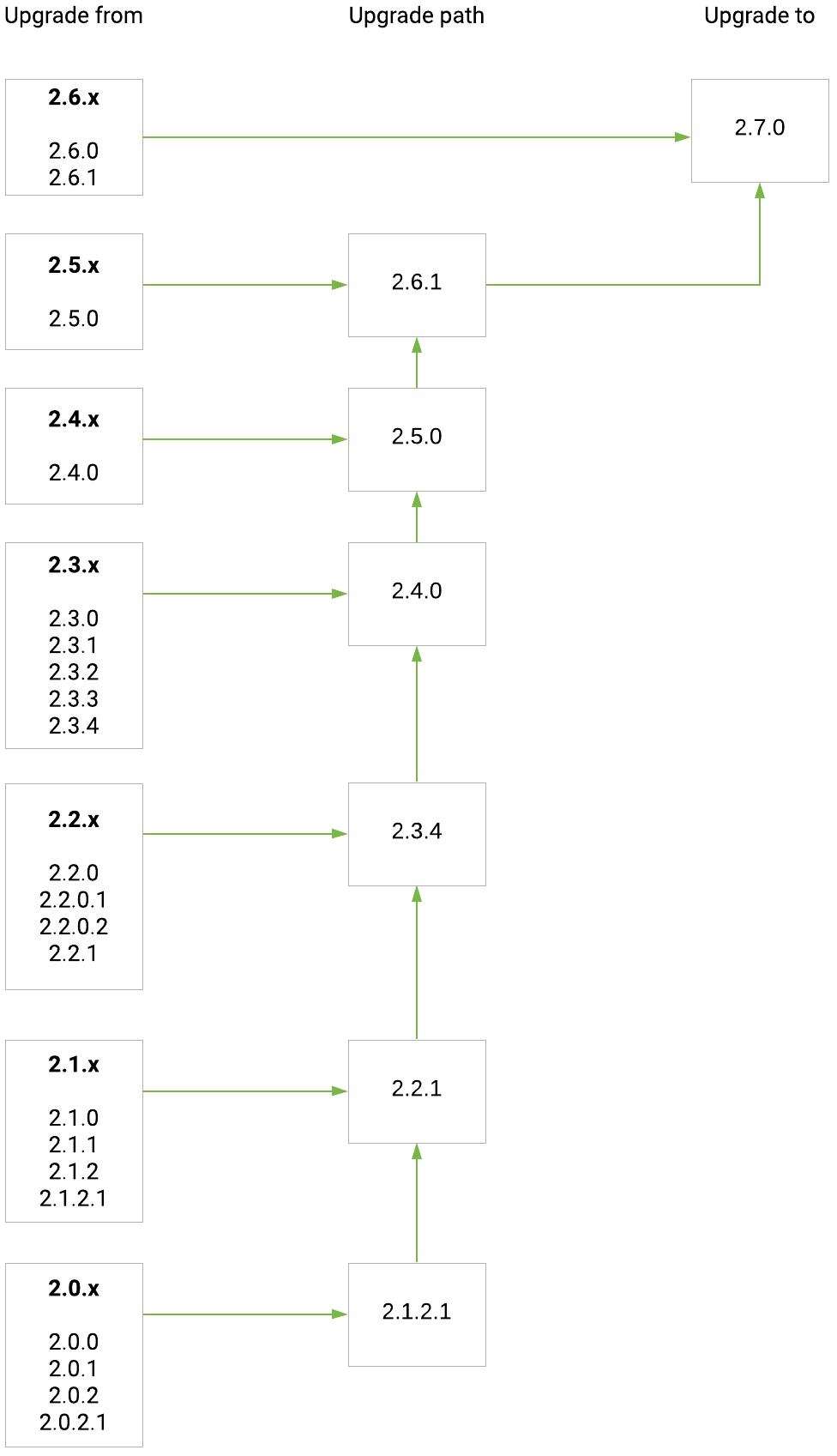
After upgrading to this release, migrate the databases.
For more information, see the platform upgrade documentation for the OS in use:
|
CentOS |
RHEL |
Ubuntu |
What's new
New features
Authentication: two-factor authentication (2FA)
When granting users access to the platform from the open internet, it is important to increase security to prevent compromising user credentials.
Two-factor authentication enables system administrators to strengthen the user authentication mechanism by adding a second authentication factor.
Two-factor authentication makes it harder for potentially malicious parties to engage in activities such as identity theft and impersonation, or unauthorized access to assets and resources.
The platform implements two-factor authentication by checking:Something users know; that is, their user name and password.
Something users have; that is, a smartphone with a compatible authentication app that generates a time-based one-time password (TOTP).
Beta features
In our quest to develop the world's most analyst-friendly threat intelligence platform, we want to understand the joys and pains of real users.
The beta feature toggle enables system administrators to give users early access to selected features we are working on, before they are officially released.
Users can safely test new features, and they can give us valuable feedback, without having to deploy a separate testing environment.Disclaimer
Beta features are beta versions of features that are still undergoing final testing before their official release. Beta features are provided on an "as is" and an "as available" basis.EclecticIQ disclaims any and all warranties, whether express or implied, as to the suitability or usability of beta features.
EclecticIQ will not be liable for any loss, whether such loss is direct, indirect, special or consequential, suffered by any party as a result of their use of beta features.
Should you encounter any bugs, glitches, lack of functionality, or other problems using beta features, please let us know immediately.You are advised to safeguard important data, to use caution, and not to rely in any way on the correct functioning or performance of beta features and/or accompanying materials.
There exists a possibility of data corruption and/or data loss.
You assume any and all risks and all costs associated with the use of beta features.Entities: create new entities in the graph (beta feature)
While investigating threats, you can easily relate new information to prior intelligence.
Add intelligence on graph enables analysts to create new entities and multiple relationships directly on the graph.
By staying on the graph, you do not need to switch contexts, and you can enjoy a smoother and more intuitive way of working.Entities: add multiple relationships at once (beta feature)
After creating several entities in the graph, you may want to also establish relationships quickly, and without switching context.
Select your source and target entities for the new relationships, click Add relationship, and publish:Graph: access control lists (ACL) in graphs
Support for Access Control Lists in graphs enables analysts to store and to share graphs without exposing restricted data to others.
This means that restricted data is not exposed to users who are not supposed to see it, but they can still use the intelligence they can access.Ingestion: improved ingestion engine (quuz)
The best hidden secret of this release is buried deep under the hood. With data ingestion streams growing every day, we upgraded the platform data ingestion engine.
More than just a component upgrade, this is the first step of a complete overhaul that we will keep building on in future releases. Enter quuz.
quuz (hint: it has the same pronunciation as "queues") is a flexible, transactional, database-backed task queue library.
quuz is the new incoming data traffic controller: it queues incoming data so that they do not clog the ingestion pipeline; it keeps an eye on running jobs and resources to minimize bottlenecks, and to optimize resource allocation in the ingestion pipeline.
The main benefit it delivers with this release is vastly improved feed isolation: incoming feeds do not interfere with each other, which greatly reduces the risk of deadlocks.Search: autocomplete saves the day
Maybe not a whole day, but it will save you some time for sure. Whether you're a new user or a very experienced one, you can search for intelligence fast.
Search autocomplete helps you create advanced search queries by offering assistance and suggestions based on your input.
Start assembling advanced search queries fast without having to master complex syntax, fields, and values; or having to ask that super expert guy for help.
{kind=link}
{kind=link}
{kind=link}
What's changed
Improvements
Search performance: entity reindexing and bulk tagging
We improved the way in which the platform processes entities while indexing or reingesting them, so that the processes now run smoother and faster.
Applying bulk changes to tags and taxonomies benefited from the improvement, too: now it takes less time to apply bulk tagging, which results in a user-friendlier experience.Data: data retention policies
Data retention policies help you handle private data prudently, and they ease compliance with legal and regulatory requirements.
Improvements to the data retention policy system enable system administrators to automatically delete private data from their databases by defining rules that are not only based on entities, but now also on observables.
This means that you can target data more precisely, and you can have more control over the data stored in your platform.Entities: choose whether to load entities into an open or new graph
In line with usability best practices, when you click an entity's Neighborhood graph, you are now able to choose between loading the entity concerned into a new graph or one that's already open.
Entities: detail pane remains open after editing
When you open an entity’s detail pane and modify its details, the detail pane will remain open and you will see the newest version of the entity. The pane was showing inconsistent behavior across the platform. This improvement gives you a more predictable workflow, and helps maintain the context of your work.Observables: automatic decrease of observable maliciousness through observable rules
In previous releases, rule-driven handling of observable maliciousness confidence level was one-way only. Observable rules could automatically assign a maliciousness confidence level, and they could subsequently change it only to increase it.
The only way to decrease the maliciousness confidence level was to manually edit the observable.
Now observable rules can both increase and decrease the maliciousness confidence level of ingested observables. If an observable is ingested again, and if its maliciousness confidence level has decreased, the new, lower value supersedes the older, higher value.
If the updated observable belongs to an entity, the platform produces a new minor version of the entity to incorporate the changes.Observables: bank account and registrar observables exported as CybOX objects
In previous releases, bank account and registrar observables were not exported as CybOX objects as part of the containing indicator XML file in a STIX package, even though they existed as extracted observables within the corresponding JSON files.
From this release, bank account and registrar observables nested in a containing entity bundled in a STIX package are included in the observable types that are extracted as CybOX, and exported as part of the resulting STIX output.Feeds: anonymize sources fields in outgoing feeds
When you configure an outgoing feed, you may want to filter out selected details from the content the feed publishes; for example, information sources; or you may want to exclude from publication data in specific JSON fields.
Besides information_source.identity.name and information_source.references, now you can filter out and replace also data in the following entity fields:sources.name
sources.source_id
sources.source_type
Feeds: exclude invalid STIX content from outgoing feeds
When you configure an outgoing feed, you can turn on or off a new option: Exclude invalid STIX .
If you select this checkbox, the platform applies stricter STIX validation checks to the feed content before packaging it for dissemination.
Entities with invalid or malformed STIX are not packaged; therefore, the outgoing feed publishes packages containing only valid STIX entities.
If you enable this option, rejected entities are logged with the message: dropped invalid entity .Feeds: robuster incoming feed purge operation
We tuned the incoming feed purging mechanism to become more resilient and robust, also when purging very large incoming feeds.
The purging mechanism now begins by deleting entities, then ingested packages, and finally the incoming feed. It splits up the workload into batches to minimize potential deadlock risks.
In case of errors, the process automatically retries multiple times. If a deadlock does occur, it does not cause a complete rollback of the whole purge action.Filters: distinguish between source filters with the same name
When filters have the same name, but concern different source types, you can now see what their source types are, thus increasing usability.Tools: eiq-platform search sync-data --changed-before
The eiq-platform search sync-data command has a new option to enable splitting a job into multiple smaller jobs.
This is useful when very large sync jobs affect platform performance.
{kind=link}
{kind=link}
{kind=link}
Important bug fixes
This section is not an exhaustive list of all the important bug fixes we shipped with this release.
In previous releases, when creating an entity, it was possible to set an Estimated threat start time that was after the Estimated threat end time .
This is no longer possible. However, it is still possible to set an Estimated observed time that is after the end time.In previous releases, it would occasionally be impossible to save a graph to a workspace because the workspaces concerned were unavailable.
This was due to undetected spikes in memory utilization. This has now been resolved, and you can always save graphs to a workspace.In previous releases it would be possible to select and to enrich an observable also with irrelevant enrichers, which would always return no matches.
For example, it would be possible to select an IP address observable, and then enrich it with an enricher for domain observables.
We fixed this inconsistent behavior, so that now it is possible to enrich an observable only with enrichers that retrieve additional information for the specified observable type.
For example, now you can enrich an IP address observable only with enrichers that provide additional context for IP addresses.In releases 2.5.0 until 2.6.1, opening an entity detail pane, adding the entity to the graph from the detail pane, and then closing the detail pane to focus on the graph would cause the graph to close.
Now you can close an entity detail pane after adding the entity to the graph, and you can keep working in the open graph.
In this release we fixed a bug that affected the configuration and edit views of incoming feeds: while it was possible to set a date and time in the Start ingesting from input field.
However, the specified values would not be stored, and subsequent feed runs would not apply them.
Now, if you specify a start date and time to start ingesting data from, the feed consistently applied these values.In previous releases it would not be possible to save a SFTP upload outgoing feed configured to publish feed content to a target server using the SFTP transport protocol.
Now it is possible to correctly set a URL with the SFTP transport protocol to point to the publishing location of the SFTP upload outgoing feed.When you create an entity rule, you can use the Path and Value pairs to specify a set of content criteria to define specific entity fields the rule should target.
The Value field would match only lowercase input, due to the way in which Elasticsearch tokenizes and stores specific entity field values.
Now any input in the Value field is pre-processed to make sure that the input is processed as a case-insensitive query.
For example, a query looking for the OceanLotus value now returns the same results as a query looking for oceanlotus.In this release we fixed a bug where a signed-in user could get their modify configurations permission revoked, and as long as they did not refresh the active GUI view in the web browser, they could still access the platform general settings edit view.
They could change settings; however, they could not save them.
Now, if a signed-in user loses their modify configurations permission, they can no longer access the platform general settings edit view.
{kind=link}
{kind=link}
{kind=link}
Known issues
When more than 1000 entities are loaded on the graph, it is not possible to load related entities and observables by right-clicking an entity on the graph, and then by selecting Load entities, Load observables, or Load entities by observable.
In case of an ingestion process crash while ingestion is still ongoing, data is not synced to Elasticsearch.
MISP content ingestion through incoming feeds can be slow down and proceed slowly.
Between consecutive outgoing feed tasks, the platform may increase resource usage. This may result in an excessive memory consumption over time.
When an enricher reaches its monthly execution cap because it exceeds the allowed maximum number of requests, it fails, and it stops without returning a helpful error message.
Together with rate limiting, execution cap helps control data traffic for the enricher; for example, when the API or the service you are connecting to enforces usage limits.In the scenario where a dynamic datasets groups entities based on their tags, and the dynamic dataset view is open in a browser tab; if you add or remove entities to the dynamic dataset by changing their tag values while the dynamic dataset view is open in the browser tab, the view does not automatically update to reflect the changed dynamic dataset content.
To update the dynamic dataset view, you need to manually refresh the browser tab.If you open a draft entity detail pane, and then if you delete the draft entity while its detail pane is still open, the detail pane does not close automatically, and it displays an error message.
Systemd splits log lines exceeding 2048 characters into 2 or more lines.
As a result, log lines exceeding 2048 characters become invalid JSON, and Logstash is unable to parse them.
Security issues and mitigation actions
The following table lists known security issues, their severity, and the corresponding mitigation actions.
The state of an issue indicates whether a bug is still open, or if it was fixed in this release.
For more information, see All security issues and mitigation actions for a complete and up-to-date overview of open and fixed security issues.
|
ID |
CVE |
Description |
Severity |
Status |
Affected versions |
|
minimist enables prototype pollution |
2 - MEDIUM (Snyk score) |
|
2.6.0 and earlier. |
||
|
- |
A signed-in user can access any datasets by adding them to workspaces they can access |
1 - LOW |
|
2.6.0 and earlier. |
|
|
- |
A signed-in user can gain unauthorized access to workspaces |
4 - CRITICAL |
|
2.6.0 and earlier. |
|
|
- |
HTML Injection into Platform Emails |
3 - HIGH |
|
2.6.0 and earlier. |
|
|
- |
HTML injection through task name |
1 - LOW |
|
2.6.0 and earlier. |
|
|
- |
Attacker can hide malicious JavaScript code in entity hyperlink |
3 - HIGH |
|
2.6.0 and earlier. |
|
|
PySAML2 before 5.0.0 is vulnerable to XML Signature Wrapping (XSW) vulnerability |
3 - HIGH |
|
2.6.0 and earlier. |
||
|
- |
A signed-in user can use platform rules to send a GET request to a remote host |
1 - LOW |
|
2.6.0 and earlier. |
|
|
- |
A signed-in user can view saved graph thumbnails |
1 - LOW |
|
2.6.0 and earlier. |
|
|
- |
A signed-in user could bypass password prompt before editing platform user details |
1 - LOW |
|
2.6.0 and earlier. |
|
|
- |
https-proxy-agent could enable main-in-the-middle attacks |
2 - MEDIUM |
|
2.6.0 and earlier. |
|
|
- |
lodash.mergewith enables prototype pollution |
3 - HIGH |
|
2.4.0 to 2.6.0 included. |
|
|
- |
Nginx sends full referrer data |
1 - LOW |
|
2.3.1 to 2.6.0 included. |
Contact
For any questions, and to share your feedback about the documentation, contact us at [email protected] .