Release notes 2.6.1
|
Product |
EclecticIQ Platform |
|
Release version |
2.6.1 |
|
Release date |
18 Mar 2020 |
|
Summary |
Maintenance release containing bug fixes. |
|
Upgrade impact |
Medium |
|
Time to upgrade |
~30 minutes to upgrade
|
|
Time to migrate |
|
EclecticIQ Platform 2.6.1 is a maintenance release. It contains a mix of fixes for bugs and minor improvements.
For more information about enhancements and improvements, see What's changed below.
For more information about bugs we fixed, see Important bug fixes below.
For more information about security issues we addressed, see Security issues and mitigation actions below.
This release does not introduce any major changes in features and functionality.
The reference product documentation for this release is the one describing EclecticIQ Platform 2.6.0.
Download
Follow the links below to download installable packages for EclecticIQ Platform 2.6.1 and its dependencies.
For more information about setting up repositories, refer to the installation documentation for your target operating system.
|
EclecticIQ Platform and dependencies |
|
|
EclecticIQ Platform extensions |
Upgrade
Upgrade paths from release 2.0.x(.x) to 2.6.1:
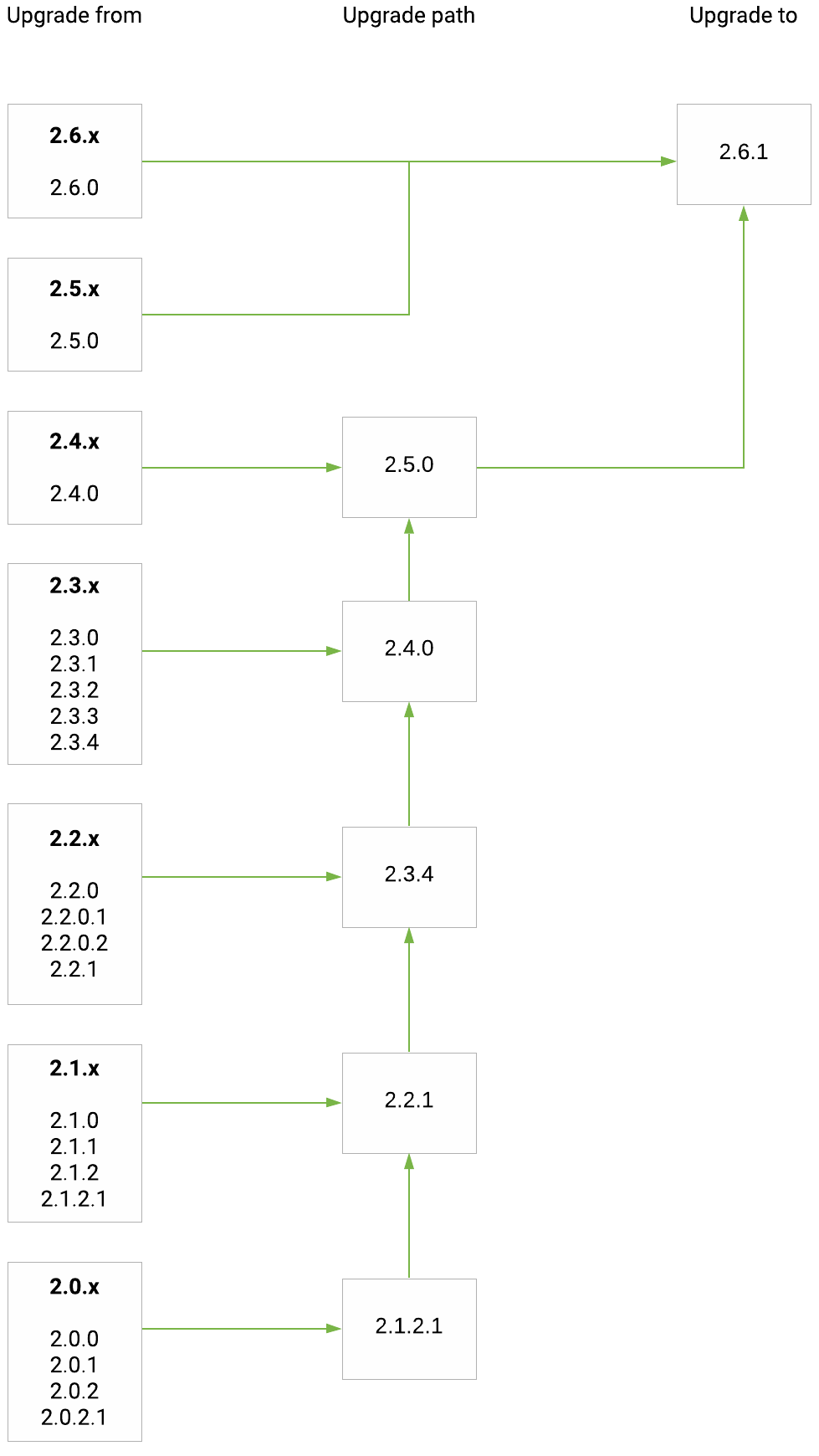
EclecticIQ Platform upgrade paths to release 2.6.1
After upgrading to this release, migrate the databases.
For more information, see the platform upgrade documentation for the OS in use:
|
CentOS |
RHEL |
Ubuntu |
What's changed
Improvements
It is now possible to update the maliciousness confidence level of observables to set it to a lower or safer level.
Previously, to reduce the maliciousness confidence level of an observable, or to flag a malicious observable as safe or irrelevant, it was necessary to edit it manually.
Sometimes enricher may be fidgety and fussy, for example because of connectivity issues or timeouts. As a result, the platform disables failing enrichers.
We made enrichers a bit more resilient: upon failure, they automatically restart and retry polling their data sources, until they reach a maximum amount of consecutive retries.
When they exceed the maximum number of retries, they are disabled.
Administrators can set the maximum number of retries by assigning an integer value to the ENRICHER_FAILURES_TO_DISABLE parameter in /etc/eclecticiq/platform_settings.py.
Example:settings.py (sourced from EIQ platform-api repo )
Author
saaj
Commit
31ac02ec3b883364009f4d624f80307ec7409e02
Timestamp
July, 31, 2020 01:09 PM
Full path
eiq/platform/settings.py
Title
[TP46975, EIQ-3964] Digital Shadows - key error - 2.6 (#4974)
Description
* Port from 2.7 * Black * Add some more tests
# Number of failures before disabling an enricherENRICHER_FAILURES_TO_DISABLE=10The eiq-platform search sync-data command to sync the Elasticsearch indexing and search database with the PostgreSQL main database has a new parameter:
--changed-before
This parameter complements --changed-after.
--changed-before and --changed-after enable dividing a database sync job into batches to reduce the load on system resources.We improved ingestion performance by refining access control list data caching related to observable data sources.
By default, this option is set to False (disabled).
Administrators can enable it by changing the default value of SOURCES_ACL_REDIS_CACHE_ENABLED from False to True in /etc/eclecticiq/platform_settings.py:
settings.py (sourced from EIQ platform-api repo )Author
saaj
Commit
31ac02ec3b883364009f4d624f80307ec7409e02
Timestamp
July, 31, 2020 01:09 PM
Full path
eiq/platform/settings.py
Title
[TP46975, EIQ-3964] Digital Shadows - key error - 2.6 (#4974)
Description
* Port from 2.7 * Black * Add some more tests
# Observable source ACL caching. This can improve performance of some ingestion# scenarios, at the cost of seeing potentially outdated data.SOURCES_ACL_REDIS_CACHE_ENABLED=False
Important bug fixes
This section is not an exhaustive list of all the important bug fixes we shipped with this release.
When creating an outgoing feed with SFTP upload content type, it would not be possible to successfully save a URL with the sftp:// protocol in the SFTP server URL field.
Now the the sftp:// protocol is validated correctly, and it is possible to correctly configure an SFTP outgoing feed.IP observables would erroneously be associated with enrichers targeting domain and URI observables.
Now IP observables are associated only with enrichers retrieving contextual details that are relevant for IP observables.
Security issues and mitigation actions
The following table lists known security issues, their severity, and the corresponding mitigation actions.
The state of an issue indicates whether a bug is still open, or if it was fixed in this release.
For more information, see All security issues and mitigation actions for a complete and up-to-date overview of open and fixed security issues.
This release does not address any security issues.
Known issues
When you configure the platform databases during a platform installation or upgrade procedure, you must specify passwords for the databases.
Choose passwords containing only alphanumeric characters (A-Z, a-z, 0-9).
Do not include any non-alphanumeric or special characters in the password value.
Systemd splits log lines exceeding 2048 characters into 2 or more lines.
As a result, log lines exceeding 2048 characters become invalid JSON.
Therefore, Logstash is unable to correctly parse them.When more than 1000 entities are loaded on the graph, it is not possible to load related entities and observables by right-clicking an entity on the graph, and then by selecting Load entities, Load observables, or Load entities by observable.
When creating groups in the graph, it is not possible to merge multiple groups to one.
In case of an ingestion process crash while ingestion is still ongoing, data is not synced to Elasticsearch.
Users can leverage rules to access groups that act as data sources, even if those users are not members of the groups they access through rules.
Between consecutive outgoing feed tasks, the platform may increase resource usage.
This may result in an excessive memory consumption over time.
Contact
For any questions, and to share your feedback about the documentation, contact us at [email protected] .