Release notes 2.13.0#
Product |
EclecticIQ Intelligence Center |
|---|---|
Release version |
2.13.0 |
Release date |
21 July 2022 |
Summary |
Minor release |
Upgrade impact |
Medium |
Time to upgrade |
~18 minutes to upgrade an instance with 4 million entities.
Additional ~6 minutes to run pre-upgrade scripts for upgrading from 2.8.x and earlier. |
Time to migrate |
|
Highlights#
EclecticIQ Intelligence Center 2.13.0 is a minor release. Apart from bug fixes, it contains improvements to three existing features that let you further automate your workflow.
First, we’ve enhanced the rules feature. EclecticIQ Intelligence Center 2.13 offers extra content criteria for creating rules that give you greater control over any additional automation you require. Rules can now contain unlimited query statements. And you can combine AND and OR conditions. This extra flexibility and granularity supercharge your custom rule-based automation and minimizes your time spent performing manual operations.
Second, release 2.13 further enhances the way EclecticIQ Intelligence Center automatically creates audit logs. Besides logging who did what, you can now also report on who saw what – down to the level of the individual objects that were accessed. And EclecticIQ Intelligence Center can now automatically stream these logs to central logging servers for you to perform your own analyses. These enhancements give you reassurance that any user action is traceable and provide more flexibility to produce the audit trails you need.
Finally, with this release we have upgraded the built-in server from TAXII 1 to TAXII 2. This means you will enjoy a much easier implementation for providing an automated intelligence feeds in STIX 2.1 format to multiple stakeholders or security controls over TAXII. And we will also be making this new TAXII 2.1 server functionality available to the community via our popular open-source tool, OpenTAXII.
We hope you enjoy reading these release notes – once again accompanied by short feature videos for your convenience – and watching the quick tour video from the team.
Video: Introducing EclecticIQ Intelligence Center 2.13#
What’s new#
Complex content criteria for entity rules#
You can now create complex content criteria for entity rules. This allows you to set up entity rules to conditionally match values found in given fields of an entity object.
To start using complex content criteria:
Create a new entity rule by going to Data configuration
 > Rules > Entity > Create
entity rule (+).
> Rules > Entity > Create
entity rule (+).Select Criteria selection > Content criteria to start adding conditions to your entity rule.
For more information, see About criteria for entity rules
Note
Known issue: Predefined items in the Path field may not contain correct JSON paths.
When setting up content criteria for entity rules, you can select from predefined Paths to create rules. Some of these predefined JSON paths are no longer valid, but have not been corrected in this release.
Instead, users should manually enter JSON paths for their entity rules.
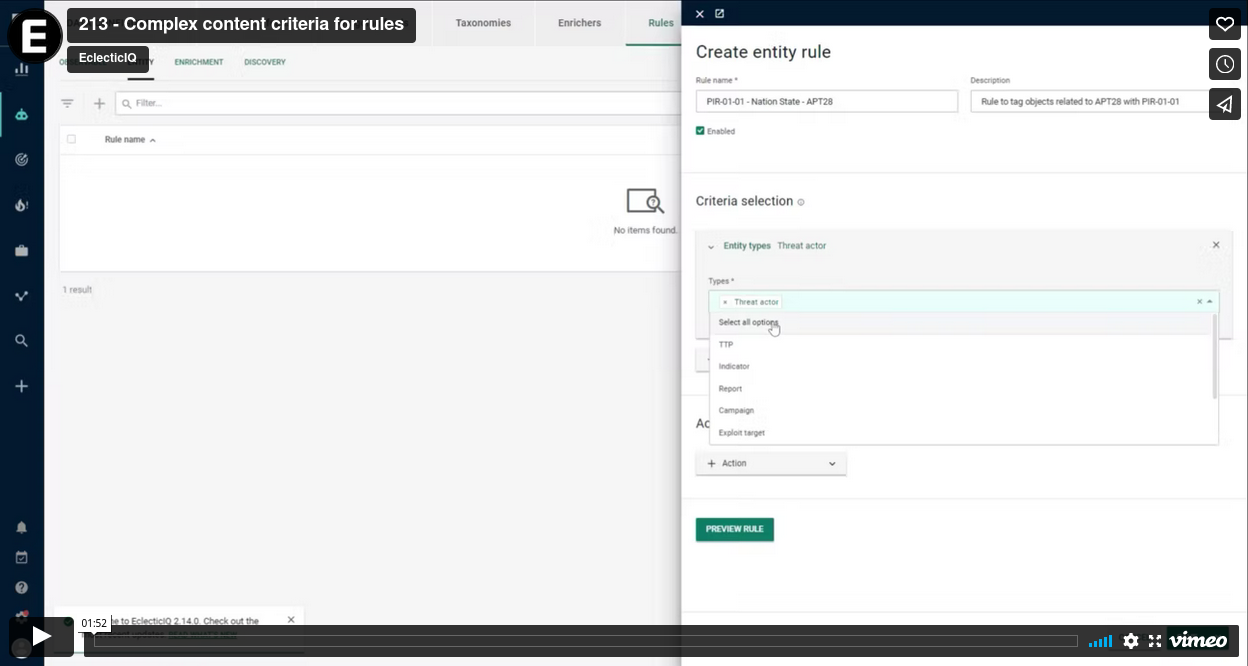
Video: Complex entity rules with new content criteria tool#
Adds TAXII 2.1 poll outgoing feed#
This release upgrades the bundled OpenTaxii server. This brings support for hosting TAXII 2.1 collections as outgoing feeds to the Intelligence Center.
Now, you can set up a TAXII 2.1 poll outgoing feed to create TAXII 2.1 collections that users can poll to retrieve data.
For more information, see Outgoing feed - TAXII 2.1 poll.
Note
By default, the TAXII 2.1 discovery
endpoint is made publicly available at
https://{ic_url}/taxii2/.
To restrict access for TAXII 2.1 endpoints to only authenticated users, see the documentation.
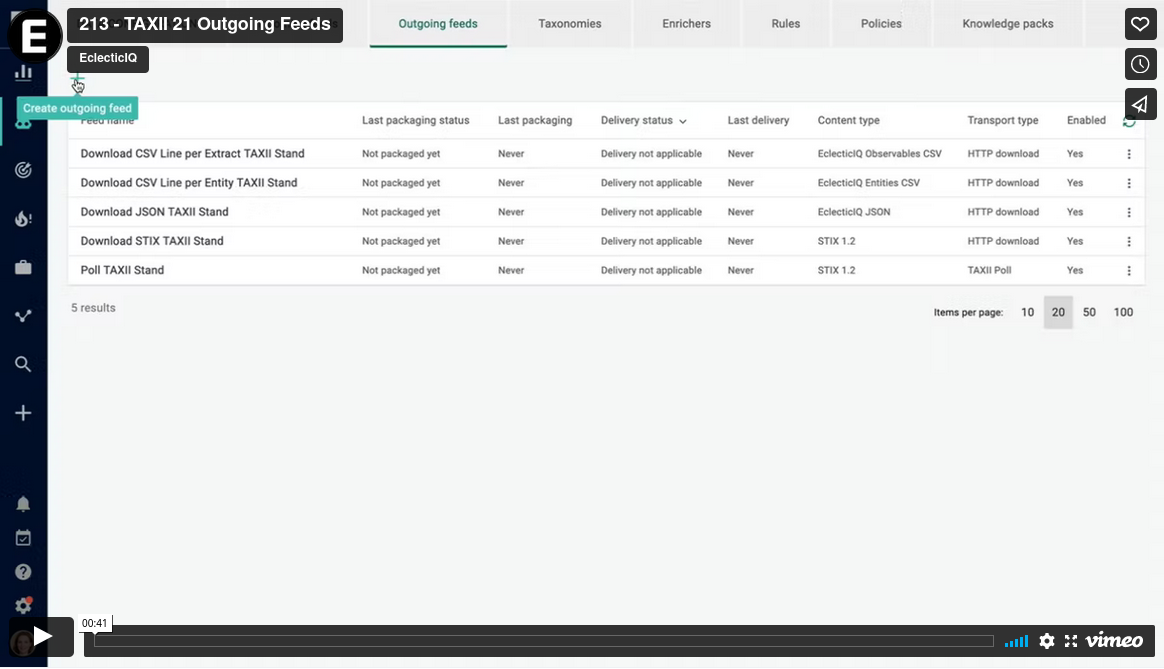
Video: TAXII 2.1 poll outgoing feeds#
Extended audit logs#
This release extends the IC’s audit logging capabilities.
Previously, audit trail logs captured only write requests
made to the IC (PUT, POST, DELETE requests). With
extended logging:
the audit trail log now contains additional fields that can identify the requestor and the requested objects.
you can now configure the IC with two additional log levels:
read-writeandextended read-write.
Setting AUDIT_TRAIL_LOG_LEVEL = "extended read-write" produces a high log volume. Adjust
AUDIT_LOG_RETENTION to limit the amount of space audit
trail logs will take up.
By default, this
is set to 360 days (AUDIT_TRAIL_RETENTION = 360).
Note
Changes to the audit trail log are not yet available in the UI. Access the Kibana console on your IC instance to see the logs captured by extended audit trail logging features.
To access Kibana on your IC instance:
Sign in on your IC instance.
Go to
https://{ic-url}/private/kibana/app/kibana#.In the left navigation menu, go to Stack Management > Index patterns > Create index pattern to create an index pattern named
audit*.Then, go to Discover and select the
audit*index pattern to see your audit trail records.
For more information, see the Audit trail log documentation.
Video: Extended audit logging#
Fixes#
Incorrect search result count:
Fixed an issue where the count of search results displayed when searching for entities would display the number of results from a previous search.
Estimated threat end time should not be a required field:
When editing an entity’s Estimated time > Start time or Estimated time > End time fields, the Estimated threat end time field should not be mandatory. Now, that field is optional when selecting the edit button for either field.
Upload files panel would not show selected source if more than one source is available:
When manually uploading files through Create (+) > Upload, the Upload files panel would allow you to select a Source to assign the resulting entities and observables. Fixed an issue where the selected Source would not be displayed if more than one source is available.
Preview of content in Analysis field may not display for certain entities
Fixes an issue where viewing an entity does not display a preview of its Analysis field.
UI crashes when using the report editor to add relationships to entities or observables with certain non-ASCII characters in their titles
When editing a report entity’s Summary or Analysis field, you can insert relationship to another entity or observable. However, if this entity or observable happened to have certain non-Latin1 characters in their titles, the UI would crash. Fixed in this release.
Viewing full summary of entities may display raw HTML instead of rendering content
Users can select View full content when viewing the truncated Summary or Description of a given entity. Fixed an issue where the content displayed when selecting View full content would show raw HTML instead of rendering the content.
Observables added to entities in a certain way would not retain maliciousness
While editing an entity (using the Entity Builder), a user can add observables to that entity using the + OBSERVABLE button.
This release fixes an issue where if a user adds more than one observable to the entity this way, each added observable except the most recent will have their maliciousness value set to “Unknown”.
Graphs may display incorrect “unsaved” state in title
Fixes an issue where graphs may display an incorrect “unsaved” state in its title by suffixing its title with an asterisk (
*).Note: Issue may persist when the Intelligence creation on the graph beta feature is enabled.
Confirmation dialog when deleting taxonomies not scrollable
When deleting taxonomies with children, the UI displays a confirmation dialog box that shows the list of children taxonomies that will be deleted along with the selected taxonomy. Previously, the length of that list could exceed the maximum window height for users, causing users to be unable to read the full list of affected children taxonomies. Now, the list of affected children taxonomies is scrollable.
Disabling a knowledge pack may orphan user-created datasets
Users may create datasets and assign them to workspaces that belong to a knowledge pack. When that knowledge pack is disabled or uninstalled, those workspaces are removed. This caused those user-created datasets to be inaccessible if they were not also assigned to another workspace.
Now, if a dataset belongs to only one workspace, and that workspace is removed when its parent knowledge pack is disabled, that dataset is also removed.
Dataset properties may show that they are used by outgoing feeds that do not use it
When users view the properties of a dataset by going to Search
 > Datasets, its properties
would show an incorrect list of outgoing feeds that use
the dataset. Now, datasets’ properties display a correct
list of outgoing feeds that use that dataset.
> Datasets, its properties
would show an incorrect list of outgoing feeds that use
the dataset. Now, datasets’ properties display a correct
list of outgoing feeds that use that dataset.Entities that have an invalid threat end time are skipped and logged
Issue where invalid entities with an estimated threat end time that is earlier than its estimated threat start time could be ingested from an external source to produce entities with a negative relevancy score, causing issues on the IC.
Now, entities with invalid estimated threat end times are skipped during ingestion, and are logged to the audit trail.
When running enrichers with the ‘Enrich with all’ button, and at least one enabled enricher has unset required fields, the enricher task will remain perpetually ‘PENDING’
Fixed issue where when running enrichers with the Enrich with all button, users may inadvertently run enabled enrichers that do not have the required configuration fields (e.g. credentials) set, leading to the enricher task getting stuck in a PENDING state.
Users have issues saving graphs
Fixed issue where users with non-administrator permissions:
Could not save an empty graph
Could not save a graph that contains entities that belongs to at least one source that is not one of the user’s allowed sources.
Known issues#
TAXII 2 endpoints return HTTP 500 instead of HTTP 401 with bad authentication token
When making requests to TAXII 2 endpoints with an invalid
Bearertoken, the IC responds with a HTTP 500 (Internal server error) instead of a HTTP 401 (Unauthorized) error.Entity rules: predefined Path items for content criteria may not work
When creating entity rules, you can choose from a list of predefined Paths when setting up Content criteria.
These predefined Paths currently do not work. Instead, set up Content criteria for your rules by manually entering JSON paths.
Delete observable actions in policies may cause policies to run for excessively long periods of time.
As of 2.12.0, Delete observable actions are skipped by default to allow policies to run more reliably.
Elasticsearch 7 encounters “Data too large” errors: See Elasticsearch 7: “Data too large”.
Systemd splits log lines exceeding 2048 characters into 2 or more lines.
As a result, log lines exceeding 2048 characters become invalid JSON, causing Logstash to be unable to parse them correctly.
When more than 1000 entities are loaded on the graph, you cannot load related entities and observables by selecting Load entities, Load observables, or Load entities by observable from the context menu.
When creating groups in the graph, it is not possible to merge multiple groups into one.
If an ingestion process crashes while ingestion is still ongoing, data may not always sync to Elasticsearch.
Users can leverage rules to access groups that act as data sources, even if those users are not members of the groups they access through rules.
Running multiple outgoing feed tasks may cause the Intelligence Center to consume a large amount of memory over time, because certain outgoing feeds such as HTTP download must load the data into memory in order to make it available to feed consumers.
Download#
For more information about setting up repositories, refer to the installation documentation for your target operating system.
EclecticIQ Intelligence Center and dependencies for CentOS and RHEL |
|
|---|---|
EclecticIQ Intelligence Center extensions |
|
Upgrade#
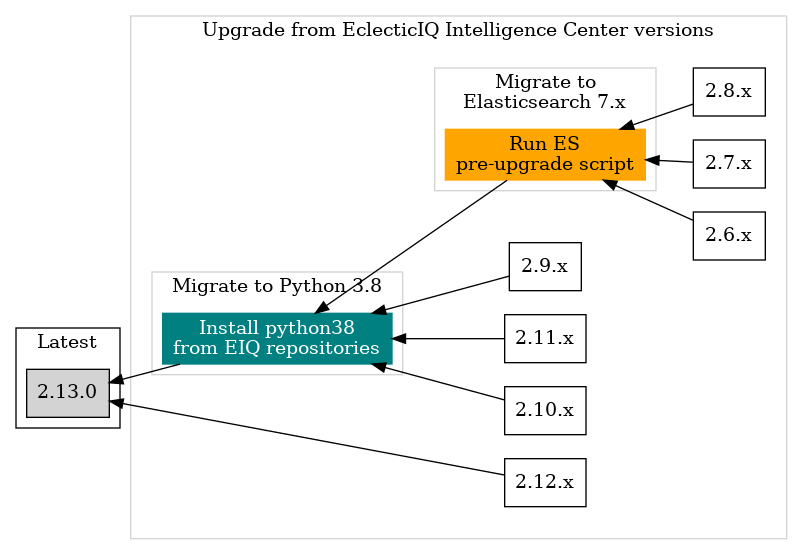
The following diagram describes upgrade paths available.
When upgrading from 2.8.x and earlier to 2.9.x and later:
You must run the pre-upgrade script to allow it to work with Elasticsearch 7.9.1.
You must run the pre-upgrade script on the Intelligence Center version you are upgrading from.
For example, when upgrading from 2.8.0 to 2.10.1, you must run the pre-upgrade script on the Intelligence Center while it is running version 2.8.0.
When upgrading from 2.11.x and earlier to 2.12.x and later,
you must install the EIQ-provided python38 package.
For more information, see the upgrade instructions for your OS.
Upgrade diagram#
These upgrades paths have been tested using the EclecticIQ Intelligence Center install script compiled by Rundoc.
The script only supports:
Single machine installs.
Instances installed using the Intelligence Center install script.
and does not support Intelligence Center instances installed in distributed environments.