Release notes 2.2.0
|
Product |
EclecticIQ Platform |
|
Release version |
2.2.0 |
|
Release date |
2018-06-29 |
|
Summary |
|
|
Upgrade impact |
- |
|
Time to upgrade |
- |
|
Time to migrate |
- |
Highlights
EclecticIQ Platform 2.2.0 brings you more flexibility and more granular control over the data stored in the platform, and who can access it.
The platform records all ingestion sources for an entity to preserve all the available context about an entity origin as the entity evolves, is edited, updated, and shared across communicating platform instances.
Observables inherit their access permissions from their parent entities; this keeps the access pipeline transparent and predictable.
When you set up an outgoing feed to publish intelligence, you can exclude specific enrichment data, so that the published feed content does not include sensitive data that should not be shared outside of the organization, or enrichment data that is not supposed to be redistributed, according to licensing terms.
Last but not least: the platform documentation is available online: log in to https://docs.eclecticiq.com/ with your EclecticIQ login credentials to find guides and articles that help you with installation, configuration, upgrade, and other tasks.
{kind=link}
Further on in this section you can read a short recap of the main new features shipping with EclecticIQ Platform 2.2.0.
For more details about new features introduced in this version, see What's new below.
For more details about enhancements and improvements, see What's changed below.
For more details about bugs we fixed, see Important bug fixes below.
Multiple data sources
The platform can ingest the same entity from more than one source. While the entity data is deduplicated during ingestion, available information about the data sources the entity originates from is retained in a list of sources.
Before this release, during deduplication any ingested duplicate entities were dropped. As a consequence, any additional timestamps, tags, taxonomies, and source overrides were lost, and entity access control was tied only to the original data source.
Now entities retain relationships to all the data sources they are ingested from:
Identical entities ingested from multiple sources are processed again through the appropriate rules;
Duplicate properties such as TLP and half-life are merged intelligently;
Entity access control depends on all the data sources the entity comes from: the right to access one data source grants users access to the entity.
This provides more insight and it allows to more accurately assess data ingested from more than one source. It also enables data exchange between two platform instances without losing the original data source information of the entities.
CSV format compatibility
The EclecticIQ JSON and CSV document formats are updated to include this feature.
Therefore, they are not compatible with older releases of the platform (2.1.2 and previous versions), and they are not compatible with integrations that consume EclecticIQ JSON and CSV document formats that do not support multiple sources, such EclecticIQ Platform App for Splunk.
Consider upgrading apps and other integrations to their corresponding latest versions to consume the latest EclecticIQ JSON and CSV document formats.
ACL for observables
Before this release, any platform user could view any observables stored in the platform because observables had unrestricted access. If platform access is shared among heterogeneous groups of users, this could expose sensitive metadata, such as many Tor exit node IP addresses.
Now observable access is based on inheritance: observables inherit the same set of access controls and permissions as the entities or enrichment objects they are related to.
Exclude enrichment content from outgoing feeds
You can filter out selected enrichment data from outgoing feeds to exclude from publication any data related to the specified enrichment sources.
This option allows selective publishing, so that you can share meaningful information while withholding any sensitive enrichment data not meant for redistribution.
Online documentation
As per this release the platform documentation is available online, and it is fully searchable: log in to https://docs.eclecticiq.com/ with the EclecticIQ login credentials you normally use to access the Customer Support Portal.
We update the platform online documentation regularly; therefore, we encourage you to use it as the main documentation source for the platform.
Making the documentation available online is a first step toward applying a continuous delivery process to it.
Offline documentation is shipped with this release, but we are phasing out offline documentation availability: it will be deprecated from release 2.3.0.
What's new
New features
Ingestion and enrichment
You can manually set TLP override and source reliability values value to manually uploaded files with the new Override TLP and Source reliability drop-down menu options. (15981)
These actions are not part of the manual upload process, so that you can add these flags to make sure that sensitive information is shared with the appropriate audience, and to help other user assess how accurate and trustworthy the uploaded information is.
Dissemination
When you configure outgoing feeds, you can select one or more enrichment sources whose enrichment data you do not want to include in the outgoing feed content. (16752, 16753, 19014)
Based on your selection in the Exclude enrichments from the following sources option, the outgoing feed excludes from publication any data related to the specified enrichment sources.
This option allows selective publishing, so that you can share meaningful information while withholding any sensitive enrichment data not meant for redistribution.Data exchange reliability improvements means that the UI provides more complete and clearer information on feed status. (18901)
This makes it easier to decide when you need to act – for example, in case of failures. Transparent status information provide more explicit actionable context to help users understand what action they should carry out.
Ingesting data through incoming feeds is a multi-step process:Data ingestion: the incoming feed fetches the content to download it to the platform
Data processing: the platform processes the downloaded content to unpack the data, deduplicate it, create entities and observables, wire relationships, and store the results to the database.
The UI displays separate status information for the data ingestion/data download step, and for the data processing one. In case of failures or errors, it is easier to understand which step requires attention and possibly action from users.
When necessary, you can decide whether you want to download the content again – you may want to do this if ingestion fails; or if you want to process again the already downloaded content – you may want to do this when the feed could download the content, but it failed processing the data.
The latter option allows processing again already downloaded packages that did not correctly complete the data processing step, except any failed packages flagged to be ignored.
If you experience repeated ingestion or processing failures, it is likely that the issue lies with the feed content – for example, the package may be damaged or corrupt.
Besides deleting the package, you can now choose to simply ignore failed packages. This option hides future error messages for the selected package to ignore. However, the package content is stored in the platform, in case you want to try and download it in the future for further analysis or investigation.
You can access this feature on the incoming feed detail pane:In the top navigation bar click Data configuration > Incoming feeds > ${incoming_feed_name} > Ingested packages tab > Retry ingesting all failed
In the top navigation bar click Data configuration > Incoming feeds > ${incoming_feed_name} > Ingested packages tab > Ignore all failed
{kind=link}
{kind=link}
{kind=link}
Disseminating data through outgoing feeds is a multi-step process as well:
Data packaging: the outgoing feed fetches the content from the platform and packages it for publication.
Data delivery: the outgoing feed delivers the packaged content.
Similarly to incoming feeds, outgoing feeds show separate status information in the UI for the data packaging step, and for the data delivery one.
When necessary, you can decide whether you want to trigger again the last delivery run – you may want to do this when when you experience connectivity issues.
Depending on the configured transport type for an outgoing feed, the delivery mechanism can be based on pushing content or polling for content.
You can manually trigger delivery runs only when the transport mechanism pushes content.
You can access this feature on the outgoing feed detail pane:
In the top navigation bar click Data configuration > Outgoing feeds > ${outgoing_feed_name} > Details tab > Run now
Entities and observables
You can search for entities by selecting more than one data source from the
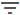 Sources quick filter. (17318)
Sources quick filter. (17318)
When an entity has more than one data source, a counter is displayed next to the main entity data source name under the Source column.
Click it to view a tooltip with a list of all the data sources the entity refers to.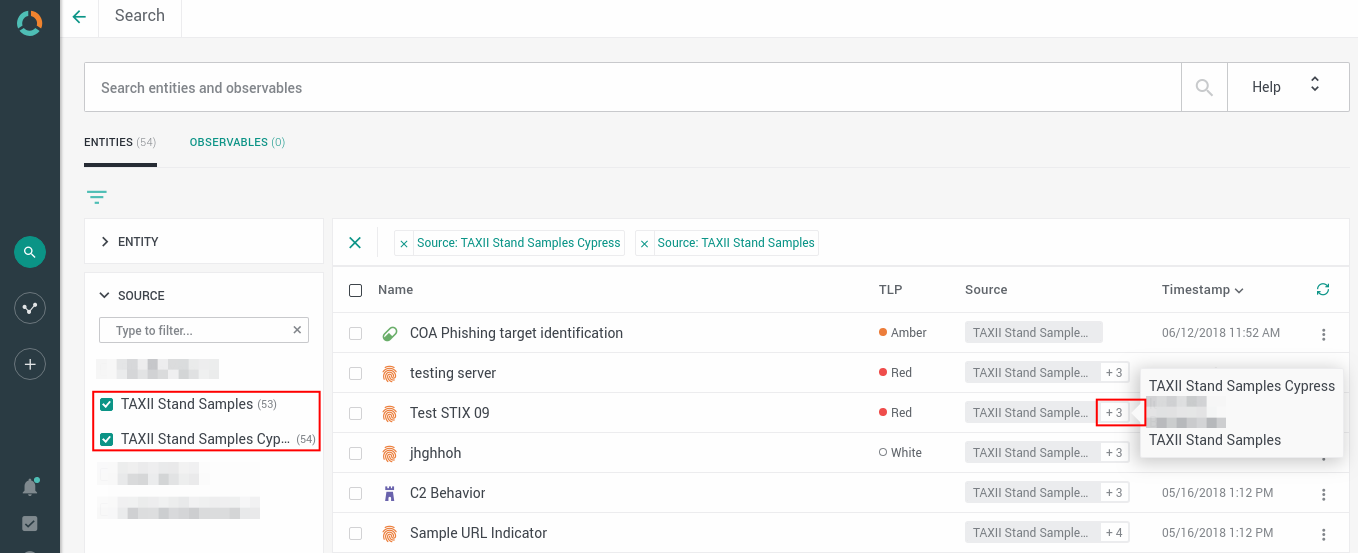
Multiple entity data sources with the Sources quick filter selectionMultiple data sources for an entity are indexed, and they are searchable.
Multiple data source information for an entity is stored in the sources JSON field as an object array.{"sources": [{"name":"TAXII Stand Samples Cypress","source_id":"09d01570-476d-4515-a458-faddb43hse86","source_type":"incoming_feed"},{"name":"test.taxiistand.com","source_id":"0bd6014d-e0b4-a8d5-83ac-c107fd034855","source_type":"incoming_feed"},{"name":"TAXII Stand Samples","source_id":"fc602bf6-f653-1234-8dde-b939f2bb13bd","source_type":"incoming_feed"}]}
Access control list (ACL) for observables.
Observable access is based on inheritance: observables inherit the same set of access controls and permissions as the entities or enrichment objects they are related to.Manual deletion of single or multiple observables at once (17021)
Observable information can change quickly, and your cyber threat data model needs to keep up with real-life changes to remain accurate. You can manually select and delete observables that are not linked to any other data in the platform, or that have become redundant.
You can manually delete dangling observables, that is, the result of manual creation at some point in the past, or whose related entity may have been deleted. You can also delete observables with relationships, if they are not valuable any longer. In the latter case, after deleting the platform creates a new version of the entity without a relationship to the now deleted observable.
You can delete observable one by one or in bulk.
Single deletion:in the top navigation bar click Intelligence > All intelligence > Browse or Intelligence > All intelligence > Production , and then the Observable tab.
On the observable overview select the observable you want to delete, then click > Delete observable.
Alternatively:
On the observable overview select the observable you want to delete.
On the observable detail pane select Actions > Delete observable.Bulk deletion:in the top navigation bar click Intelligence > All intelligence > Browse or Intelligence > All intelligence > Production , and then the Observable tab.
On the observable overview click the checkboxes to select the observables you want to delete, and then on the top-right corner above the overview table click > Delete observables.
> Delete observables.You can now apply more granular access control list (ACL) permissions on observables to make sure that sensitive information is shared with the appropriate audience, and to prevent inadvertently disclosing sensitive observable information to unintended audiences. (19185)
Whereas ACL at entity level is based on allowed sources and TLP flags, ACL at observable level is based on inheritance: observables inherit access rights and permissions from either the entities or the enrichment object – an enrichment observable or an enrichment entity – they have direct relationships with.
Therefore, you can see an observable if it has at least one direct relationship with an entity or with an enrichment object you have read access to.
Observables with no direct relationships to any entities or with any enrichment objects inherit user access control rights from the source they originate from.
UI
User management
Administrators can demote themselves to non-admin only if there is at least another active platform administrator profile. (16959, 17156)
If there is only one platform administrator profile, they first need to promote another user to admin, and then they can demote themselves to non-admin.Administrators can request users to reset their password to regain access to their account, for example if they get locked out or if their account gets compromised.
Users can request an account password reset to change or to reset their current password.
They may wish to click the Reset password link on the sign-in page if they forget their password, or in case they suspect that their account is compromised.
System
You can install the platform in offline mode. If you opt for an offline installation, you can mirror our package repositories from downloads.eclecticiq.com to a target location on your network, so that you can install the platform onto offline or air-gapped systems.
EclecticIQ Platform packages and all required dependencies are available on downloads.eclecticiq.com.
To retrieve the necessary resources for an offline platform installation you need to mirror the appropriate OS package repository – either CentOS, RHEL, or Ubuntu – the EPEL extra packages, if your target OS is either CentOS or RHEL, and downloads.eclecticiq.com.You can use rundoc to upgrade EclecticIQ Platform as a virtual appliance shipped as a VM image.
As per this release, The 2.2 VM requires our “recommended” CPU and memory settings. Previously we required our “minimal” CPU and memory settings. To run the 2.2 VM 8 CPUs and 32G of memory are required. Customers can lower these requirements but, depending on usage, the correct behavior of the platform is not guaranteed.
What’s changed
Enhancements
Ingestion and enrichment
Ingestion logic was refactored to improve modularity, flexibility, and speed across the whole ingestion pipeline. (16069)
Dissemination
The EclecticIQ Entities CSV content type to publish content in CSV format through outgoing feeds is updated to correctly accommodate multiple entity data source information. (17376)
Entities and observables
Consistent handling of TLP color code values based on TLP (18900)
UI
You can now create and edit feeds, entities, observables, datasets, rules, and other platform objects inside their dedicated detail panes, instead of being redirected to a new page. (16390)
This enhancement improves user experience by reducing distractions and by keeping you in your current flow and context.UI enhancements to improve and simplify user experience (14109)
User management
Administrators can no longer set/change user password. They can deactivate the account or ask the user to reset it.
The user profile page was refactored to address some behavior ambiguities: (16959)
A platform administrator cannot toggle their active/inactive profile status any longer.
A platform administrator can enable and disable other admin profiles, but not their own. If they want to toggle their active/inactive profile status, they need to ask another platform administrator to do so on their behalf.If a platform instance has only one platform administrator, they cannot remove their administrator rights.
Before revoking their admin rights, they need to promote another user to administrator.
User management UX improvements (17169
Add action bar for bulk actions on user management page (17763, 17167 )
Add search bar on user management page (17170)
Add filters on user management page (17166)
User detail pane changes (17142)
System
As per release 2.1.2 you need to set up an email server for the platform before you proceed to configure email settings in the platform system settings.
If you skip this step, you will still be able to configure email settings in the platform.
However, the platform won't be able to send any automatic notification messages, and it won't be aware of any platform user email addresses.
The platform needs a configured email server to successfully create platform users and to send password reset emails when users request it.
The default email server shipped with the platform is Postfix.The Epel repository for CentOS and RHEL OSs is no longer a platform installation requirement, and it can be removed.
From this release we ship our VMware virtual machine image with OS and platform user accounts without any predefined passwords.
The root OS user account is disabled.
On first boot users are prompted to create an unprivileged OS user account that can be granted sudo privileges.
On first boot users should create at least one platform user account by running the following command:
sudoeiq-platform user create
From this release, a VM version of the platform requires our recommended CPU and memory settings to run.
A VM version of the platform running on a machine with lower settings and configuration may negatively impact platform performance and normal operation.
Documentation
The platform documentation is available online, it is fully searchable, and you can export it to PDF for offline reference.
Go to https://docs.eclecticiq.com and log in with the EclecticIQ login credentials you normally use to access the Customer Support Portal.
If necessary, contact us to obtain this information, along with any required authentication and authorization credentials to access the resources.
From the documentation home page you can browse through the product documentation, you can look for specific topics, as well as search content using free text and wildcards.
You can export and download PDF copies of specific articles or sections for offline reference.We update the platform online documentation regularly; therefore, we encourage you to use it as the main documentation source for the platform.
Making the documentation available online is a first step toward applying a continuous delivery process to it.Offline documentation is shipped with this release, but we are phasing out offline documentation availability: it will be deprecated from release 2.3.0.
Rundoc usage to install the platform using a script is documented. (17688)
Important bug fixes
The following section gives an overview of the most important bug fixes to provide context and scope.
Ingestion and enrichment
Ingestion performance improvements when ingesting from a configured mount point. (13347)
Making changes to a feed would not correctly update the time of the last update. (16663)
In incoming feeds, it would not be possible to manually override the TLP value with the Not set option. (17266)
During a manual file upload with the Skip extraction of observables from unstructured text option selected, some structured observables would not be ingested. (17684)
STIX ingestion may fail when relative namespace URI conflicts with XML C14N would occur. (17796)
Addressed and issue affecting observable idref resolution whereby the metadata and the observable data resolving an idref for an observable nested in an ingested entity would not be merged to resolve the idref. (17810)
Entities and observables
The Skip paths feature available in outgoing feeds would not work correctly with HTML format report entities. (13812)
It would not be possible to manually create an indicator with more than 100 observables in the entity editor. (14879)
An exported entity in JSON format would not include the full history of the previous versions of the entity. (16442)
After modifying the search query of a dynamic dataset, the dataset entity content would not be refreshed. (16942)
It would be possible to make a POST call to the public API to create an observable with a specified type, but with an empty value. (17024)
Filtering draft entities on the Intelligence > All intelligence > Production > Draft view would return an error (17717)
It would not be possible to manually edit the of an observable, and then successfully save the changes. (17724)
A user without access to an entity can still retrieve any attachments to that entity through the public API (18900, 19094)
Search
On the UI we improved overall performance of the search page, even when the pagination size is set to 100 results per page. (12690)
Searching from within the entity view would not return results updated including the latest ingested observables. (16819)
UI
The Ingested packages tab on the incoming feed detail pane would occasionally hang and freeze when the feed was running in the background, and when its ingested queue contained a very large number (millions) of packages. (19502)
After terminating a user session, the user's browser local storage would not be completely flushed. (17388)
Addressed several issues to improve UI consistency and usability. (12784, 12837, 13000, 13342, 13456, 13797, 15536, 15608, 15633, 10529, 17537, 17595, 17172, 17709, 17712, 17809, 17915, 17971, 17987, 17995)
User management
A user with no read users permission could access the task page overview by entering the corresponding URL in the web browser. (16287)
When opening an entity detail pane in Mozilla Firefox, the detail pane would behave unexpectedly, causing the UI to hang. (16893)
System
In case of connectivity issues the backend API would keep trying to reach PostgreSQL. (16662)
The rundoc install script would not save error log information when pressing CTRL + C. (16916)
During a platform upgrade, the updated Nginx configuration would not be picked up. (17793)
Known issues
A user can create rules to access data sources that would normally be disallowed for that user. (16142)
If a user manually adds a sighting to an entity as a characteristic – in the entity editor, under Characteristics, select Characteristic > Sighting – the manually added sighting is not counted in the Exposure view. (15403)
If a user changes the title of an entity on the entity detail pane, title field, using the quick edit option , the title change is not reflected on the entity result view table under Browse, Production, Discovery, or Exposure. (9673)
This is due to the Elasticsearch index requiring a few seconds to update, apply the change, and make it available to the UI.If a user changes or resets their password, they do not receive an email message to confirm the action. (19835)
If a user creates an outgoing feed, runs it at least once to publish content, and then changes the feed transport type from one that pushes content – for example, Send email – to one that polls content – for example, TAXII poll – or vice versa, they receive an error message:
Feed configuration error error in transport or content type
It is still possible to edit the feed configuration, but it is not possible to run it successfully any longer. (19330)The Ingested packages tab on the incoming feed detail pane may hang and freeze if the feed has a very large number (millions) of packages in the ingested queue and running in the background. (19502)
When an entity is loaded on the graph, the graph does not update entity data to reflect any changes applied to the entity while it is loaded on the graph. (15462)
On the left side navigation bar, the UI button to allow user access to the graph is not available to users without the read-graph permission (16007)
In the UI, work-in-progress state and view state may sometimes not remember correctly user input or user actions. (16212)
Therefore, when a user leaves a view and then goes back to it, they may lose any input data or any changes to applied to, for example, filters, sorting, or pagination.
Contact
For any questions, and to share your feedback about the documentation, contact us at [email protected] .