Release notes 2.12.0
|
Product |
EclecticIQ Intelligence Center |
|
Release version |
2.12.0 |
|
Release date |
17 May 2022 |
|
Summary |
Minor release |
|
Upgrade impact |
Medium |
|
Time to upgrade |
~18 minutes to upgrade an instance with 4 million entities.
Additional ~6 minutes to run pre-upgrade scripts for upgrading from 2.8.x and earlier. |
|
Time to migrate |
|
Table of contents
Highlights
EclecticIQ Intelligence Center 2.12.0 is a minor release. It contains new features, improvements to existing functionality, as well as bug fixes.
This release caters to the needs of all kinds of customers. If you are mainly interested in using Intelligence Center as an intelligence repository and interacting with it programmatically, you will be pleased to hear that this release contains a completely redesigned and rebuilt API. In fact, as per this release Intelligence Center is an ‘API-first’ product, meaning that as we build new features, or update existing ones, these changes will be reflected and available in the API for you to use programmatically. And you don’t have to be a CTI expert to use the API. Check out the new developer portal to help you extend Intelligence Center within minutes: https://developers.eclecticiq.com/
If you are a CTI analyst that relies on Intelligence Center as a complete workbench for your daily investigations, you will now be less inclined to use external reporting tools. With this release we are taking the new text editor out of Beta and are unlocking more capabilities for all customers throughout Intelligence Center. This means you can create and structure reports even better, add higher quality images and screenshots to reports and use the rich text editor for all other entities and workspace descriptions as well.
Finally, this release takes a lot of repetition out of managing data. Configuring multiple enrichers at once as well as managing taxonomies just got a lot easier. And Intelligence Center can now handle network ranges as observables. So you don’t have to add each and every single IP address to express threats or targets of threats, but you can define a range of IP addresses.
We hope you enjoy reading these release notes – once again accompanied by short feature videos for your convenience – and watching the quick tour video from the team.

Video: Quick tour
What’s new
Public API v1.0
The new Public API reaches v1.0 and comes installed with IC 2.12.0.
You can find documentation and examples at https://developers.eclecticiq.com.
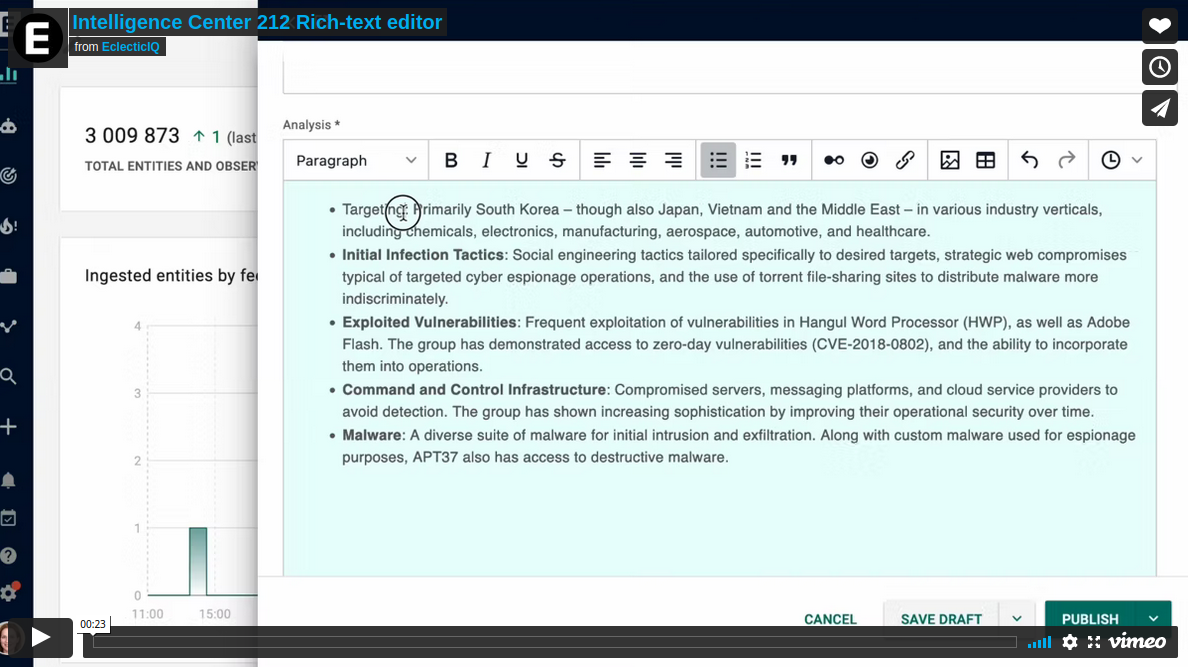
New text editor comes out of beta
This release, the entity builder switches to the new text editor, bringing a better user experience to entity creation.
With the new text editor, users get new features when creating report entities. By default, the report editor now allows you to:
Add simple tables.
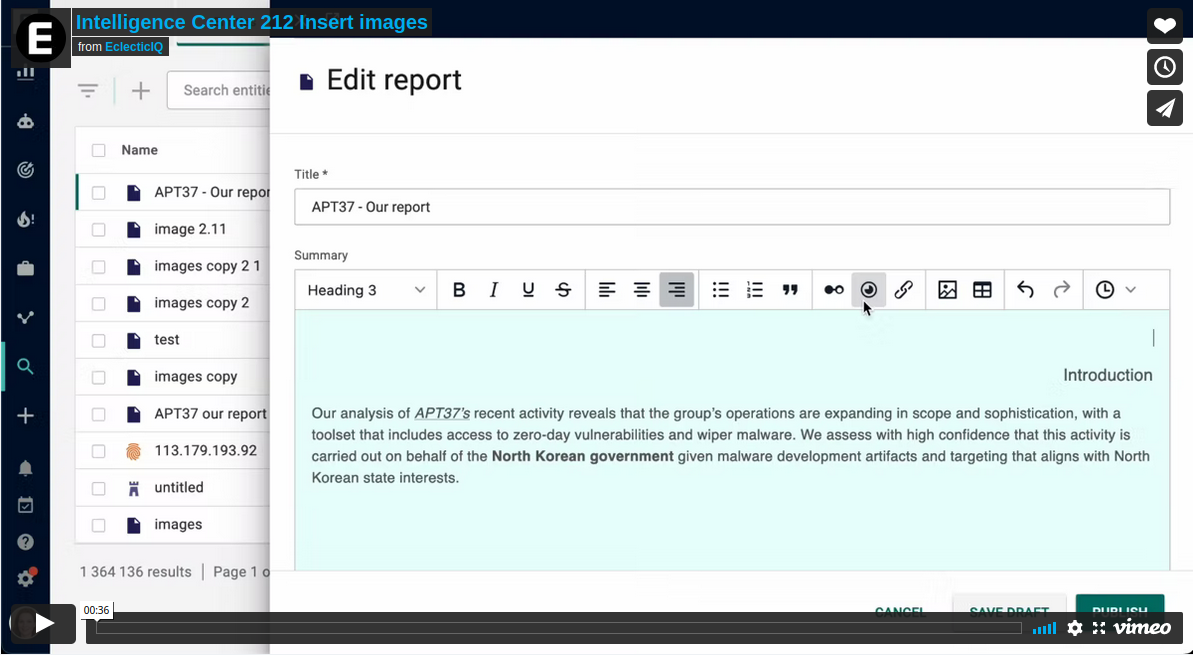
Add inline images, up to 2MB in size.
Supports these image file formats: jpeg, jpg, jpe, jfi, jif, jfif, png, gif, bmp, webp.
Resize images in the editor.
Video: Rich text editor
Video: Insert images in new text editor
Reports created with the new entity editor are backward-compatible with IC 2.11 and 2.10, with some caveats.
When importing reports created with the new editor into IC 2.11 and 2.10:
Inline images saved as entity attachments. They are not displyed when viewing the Description/Summary or Analysis fields.
Tables are displayed when viewing the report entity. However, editing and publishing the report entity removes the table and leaves only the text of the table in the field.
New enricher UI
The UI for managing and manually running enrichers has been overhauled.
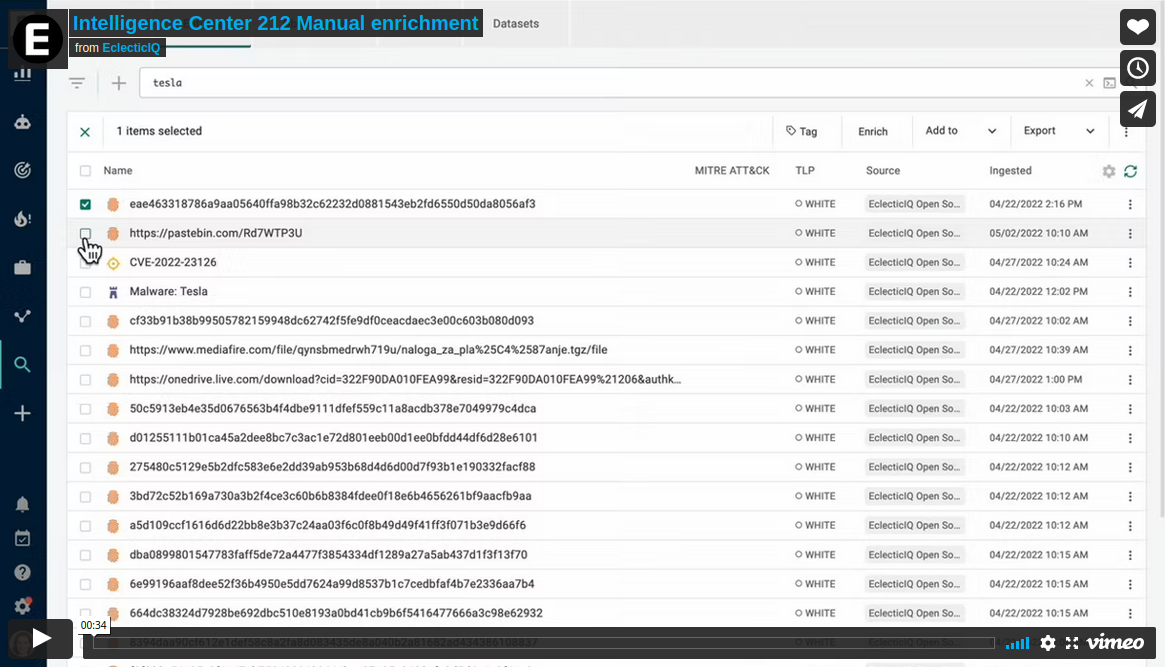
Manually running enrichers
Now when you manually enrich an entity or observable, a dialog box is displayed allowing you to select one or more enrichers to run.
Video: Manual enrichments
Configuring enrichers
The enricher overview in Data configuration ( ) > Enrichers has been improved. Enrichers are now displayed as a list instead of cards.
) > Enrichers has been improved. Enrichers are now displayed as a list instead of cards.
The new enricher overview now also allows you to:
Filter enrichers by name using either the
 Search box or the Filter (
Search box or the Filter (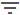 ) button.
) button.Perform bulk actions on enrichers by selecting multiple enrichers here, and then select More (
 ) to:
) to:Enable/Disable the selected enrichers,
or Edit common fields across the selected enrichers.
Video: Enricher configuration
Improved taxonomy UI
The UI for taxonomy management has been improved.
You can now filter taxonomies in Data configuration (
) > Taxonomies using the Filter (
) button, or by using the
Search box.
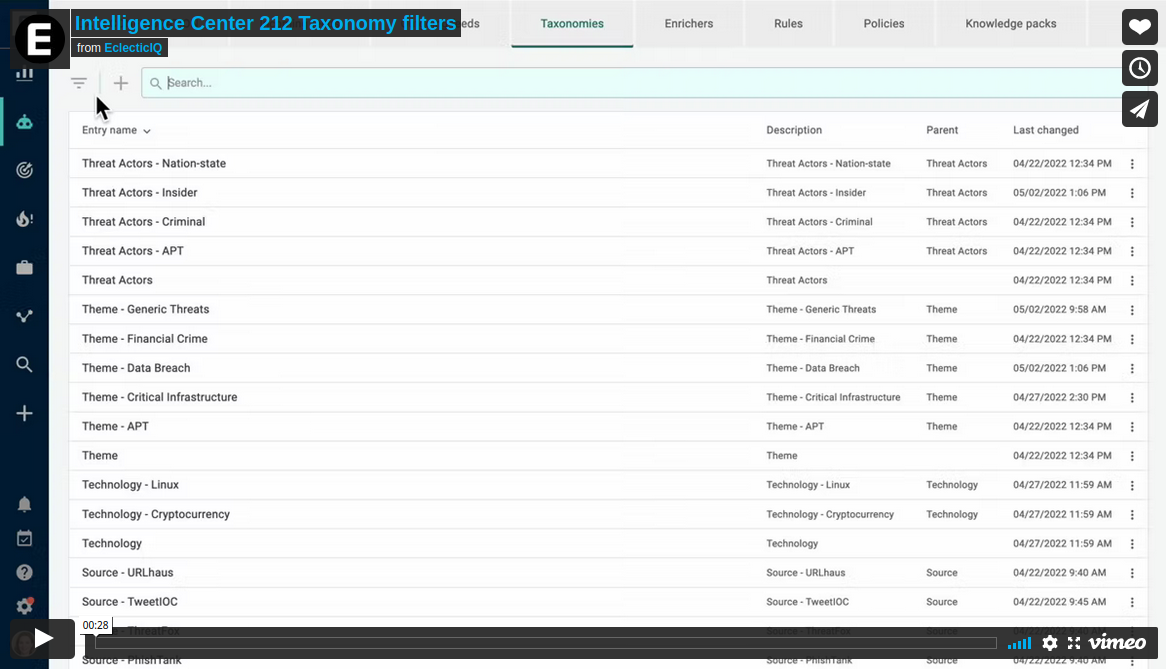
Video: Taxonomy filter
STIX 2.1: Incident SDOs and SROs
This release moves the Intelligence Center closer to STIX 2 Preferred status by adding support for the following STIX 2.1 objects:
Incident SDO (Ingestion and export)
STIX Relationship Objects (SRO) (Ingestion and export)
New observable: CIDR IP address ranges
This release adds support for working with CIDR IPv4 and IPv6 ranges. You can now:
Create Ipv4 cidr and Ipv6 cidr observables to represent an IP range.
Export CIDR observables to STIX 1.x STIX 2.1 formats.
Enrich Ipv4 cidr and Ipv6 cidr observables with the CIDR Expander enricher to produce multiple ipv4 or ipv6 observables respectively.
Expanding a CIDR observable with the CIDR Expander enricher can produce a large number of resulting observables.
To prevent this, these defaults are in place:
Maximum CIDR ranges are set. You can change this when configuring the enricher.
IPv4 default max range: /24
IPv6 default max range: /120
IC allows a maximum of 50 results from an enrichment run. Enriching CIDR ranges that result in more than 50 observables will omit the 51st observable onward.
IC 2.11.x and older cannot ingest Ipv4 cidr or Ipv6 cidr observables.
If you export an entity that is directly related to a CIDR observable as EclecticIQ JSON, and then import it into a host running IC 2.11.x or older, that entity and its observables will not be ingested.
Python 3.8
In release 2.12.0, the IC migrates to Python 3.8.
Users installing IC 2.12.0 or upgrading to 2.12.0 must use the python38 package provided by EclecticIQ to install Python 3.8. Follow the upgrade instructions for your OS:
New graph API
Graphs now use a new graph API backed by PostgreSQL and Elasticsearch, instead of Neo4j.
This release deprecates use of Neo4j, but still bundles it with the IC as a fallback graph database.
You can configure the IC to use Neo4j instead of the new graph API by changing the NEW_GRAPH_NEIGHBORHOOD_API and NEW_GRAPH_API settings in platform_settings.py. See Update platform_settings.py.
Better support for multiple Elasticsearch data nodes
You can now specify multiple Elasticsearch data nodes that the IC can connect to when querying the cluster.
Now, you should specify the network address of one or more Elasticsearch data nodes with the SEARCH_URLS attribute in platform_settings.py
This change also deprecates the older SEARCH_URL attribute in platform_settings.py.
See Update the settings.
Change in data retention mechanisms
Data retention mechanisms are being worked on to allow you to more effectively manage how long data should be kept on your IC.
This release adds:
Policy run improvements
Data retention policy runs are more stable.
Delete observable actions are skipped by default on 2.12.0.
There is a known issue with observable removal in retention policies that is being worked on. Meanwhile, Delete observable actions are skipped by default for all policies in 2.12.0. This improves the reliability of policy runs, and allows existing policies to run without modification.
(Not recommended) You can re-enable Delete observable actions with the DISABLE_OBSERVABLE_RETENTION_POLICIES attribute in platform_settings.py. See Update platform_settings.py.
Schedule removal of old records in raw data tables
You now configure the IC to automatically delete old records in the blob and content_block tables from the PostgreSQL database.
The blob table stores raw data downloaded by running incoming feeds, and the content_block table stores data prepared for consumption through outgoing feeds.
You can set the number of days to retain records in these tables with the CONTENT_BLOCK_RETENTION and BLOB_RETENTION attributes in platform_settings.py. See Update platform_settings.py.
Fixes
Links in Sightings were not rendered
Fixed an issue where links in the Analysis section of Sightings entities were not rendered.
UI crashes when use disabling a knowledge pack encounters an error
Fixed an issue where the UI would crash in a case where a user attempts to disable a knowledge pack whose sources they do not have at least read access for.
Private API endpoint for sources should not return sources user does not have access to
Fixed an issue where the private API endpoint for sources was returning more sources than the user has permissions for. This also fixes a related issue in the EclecticIQ Browser Extension, where a dropdown menu listing sources would display more sources than the user should have access to.
Autocomplete when typing entity titles was erratic
Fixed an issue in the entity builder, where autocomplete and duplicate-detection when filling out the Title field of an entity would interfere with user’s typing.
Security fixes
To see a detailed list of security issues and their mitigations, go to All security issues and mitigations.
EIQ-2022-0003
In the IC UI, drop-down menus that render user-defined item names are vulnerable to stored XSS attacks. Addressed in EIQ-2022-0003. These drop-down menus now correctly sanitize item names.
Known issues
Delete observable actions in policies may cause policies to run for excessively long periods of time.
In 2.12.0, Delete observable actions are skipped by default to allow policies to run more reliably.
Elasticsearch 7 encounters “Data too large” errors: See Elasticsearch 7: “Data too large”.
Entity incorrectly warns it is outdated: When viewing an entity, the entity may warn that it is not the latest version when it actually is. This is related to an issue where with attachments that have been deduplicated multiple times, causing issues in the final state of the entity.
When you configure the Intelligence Center databases during a Intelligence Center installation or upgrade, you must specify passwords for the databases.
Systemd splits log lines exceeding 2048 characters into 2 or more lines.
As a result, log lines exceeding 2048 characters become invalid JSON, causing Logstash to be unable to parse them correctly.
When more than 1000 entities are loaded on the graph, you cannot load related entities and observables by selecting Load entities, Load observables, or Load entities by observable from the context menu.
When creating groups in the graph, it is not possible to merge multiple groups into one.
If an ingestion process crashes while ingestion is still ongoing, data may not always sync to Elasticsearch.
Users can leverage rules to access groups that act as data sources, even if those users are not members of the groups they access through rules.
Running multiple outgoing feed tasks may cause the Intelligence Center to consume a large amount of memory over time, because certain outgoing feeds such as HTTP download must load the data into memory in order to make it available to feed consumers.
Download
For more information about setting up repositories, refer to the installation documentation for your target operating system.
|
EclecticIQ Intelligence Center and dependencies for CentOS and RHEL |
|
|
EclecticIQ Intelligence Center extensions |
|
Upgrade
The following diagram describes upgrade paths available.
When upgrading from 2.8.x and earlier to 2.9.x and later:
You must run the pre-upgrade script to allow it to work with Elasticsearch 7.9.1.
You must run the pre-upgrade script on the Intelligence Center version you are upgrading from.
For example, when upgrading from 2.8.0 to 2.10.1, you must run the pre-upgrade script on the Intelligence Center while it is running version 2.8.0.
When upgrading from 2.11.x and earlier to 2.12.x and later, you must install the EIQ-provided python38 package. For more information, see the upgrade instructions for your OS.

Upgrade diagram
These upgrades paths have been tested using the EclecticIQ Intelligence Center install script compiled by Rundoc.
The script only supports:
Single machine installs.
Instances installed using the Intelligence Center install script.
and does not support Intelligence Center instances installed in distributed environments.