Release notes 2.8.0
|
Product |
EclecticIQ Platform |
|
Release version |
2.8.0 |
|
Release date |
06 Aug 2020 |
|
Summary |
Minor release |
|
Upgrade impact |
Medium |
|
Time to upgrade |
~5 minutes to upgrade
|
|
Time to migrate |
|
EclecticIQ Platform 2.8.0 is a minor release. It contains new features, improvements to existing functionality, as well as bug fixes. It marks another milestone on our path to building a truly analyst-centric cyber threat intelligence platform.
After kicking-off a long-term development effort to upgrade the ingestion engine of the platform with release 2.7.0, we are happy to share with you that this release brings major improvements to the platform’s ingestion capability.
After upgrading your environment to EclecticIQ Platform 2.8.0, you can start reaping the fruits of our work: now ingestion processes incoming data at entity-level to let you experience significantly faster ingestion speeds.
Besides faster ingestion, this redesigned approach also enables you to scale up your system effectively to cope with heavier workloads: to ingest more data and to speed up the process, start more worker processes and let them take care of it.
We could not pack a release with only under-the-hood improvements. Analysts are always a core target audience for us, so we made sure we would include also new features to enhance their daily experience.
After introducing search history in release 2.6.0 and search autocomplete in release 2.7.0, we kept expanding on it to give analysts a powerful tool that is easy to use.
EclecticIQ Platform 2.8.0 extends search functionality with the new multiline editor, where analysts can design complex search queries, while following the entire story their query tells.
Before running a search query in the platform, syntax validation and error highlighting save time, frustration, and a headache or two.
Finally, a word about standards. The number of intelligence providers and security controls that support STIX 2.1 and TAXII 2.1 is growing. EclecticIQ is a contributor to the development of the Oasis STIX and TAXII standards.
Therefore, EclecticIQ Platform 2.8.0 marks the beginning of a new product development track toward full interoperability with the latest Oasis STIX and TAXII standards.
In this release you can ingest IOCs in STIX 2.1 format through manual upload or incoming feeds. Of course, release 2.8.0 supports TAXII 2.1 as the complementary transport type that carries STIX 2.1 data.
In the future, the platform will enable sharing STIX 2.1 indicators, as well as offer support for the other STIX 2.1 objects.
We hope you enjoy reading these release notes – now accompanied by short feature videos for your convenience – and watching the quick tour video from the team.
Follow the link and check out the new quick tour video from the team for a short rundown of these highlights.

For more information about new features and functionality, see What's new below.
For more information about enhancements and improvements, see What's changed below.
For more information about bugs we fixed, see Important bug fixes below.
For more information about security issues we addressed, see Security issues and mitigation actions below.
Download
Follow the links below to download installable packages for EclecticIQ Platform 2.8.0 and its dependencies.
For more information about setting up repositories, refer to the installation documentation for your target operating system.
|
EclecticIQ Platform and dependencies |
|
|
EclecticIQ Platform extensions |
Upgrade
Upgrade paths from release 2.0.x(.x) to 2.8.0:
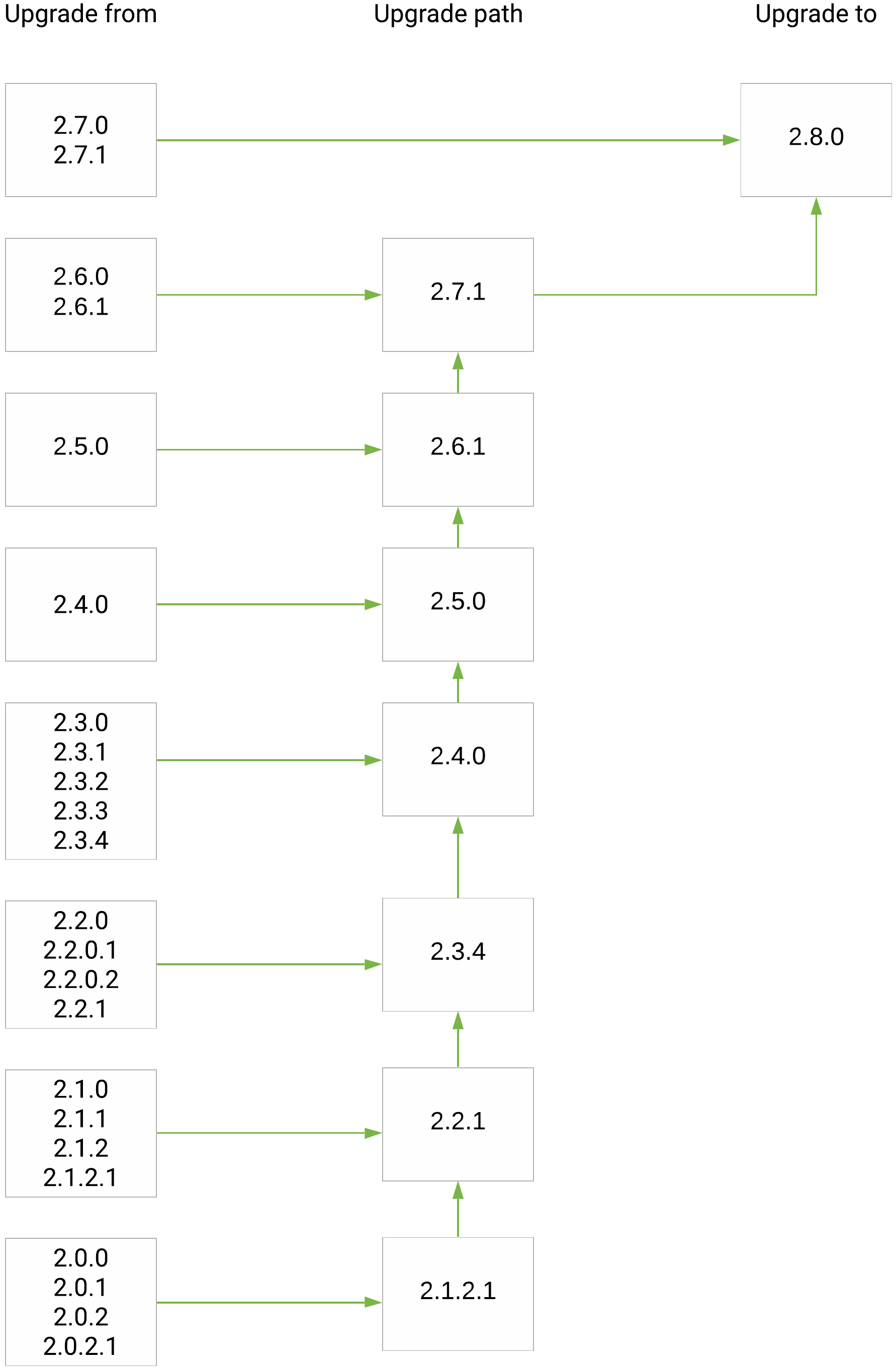
EclecticIQ Platform upgrade paths to release 2.8.0
What's new
IOC ingestion in STIX 2.1
More and more intelligence providers and security controls are implementing support for the STIX and TAXII 2.1 standards.
Take the first step towards full interoperability: the platform data model and all platform processes that rely on it have been extended to include the new Indicator domain object.
This enables ingesting and sharing IOCs in STIX 2.1 format over TAXII 2.1.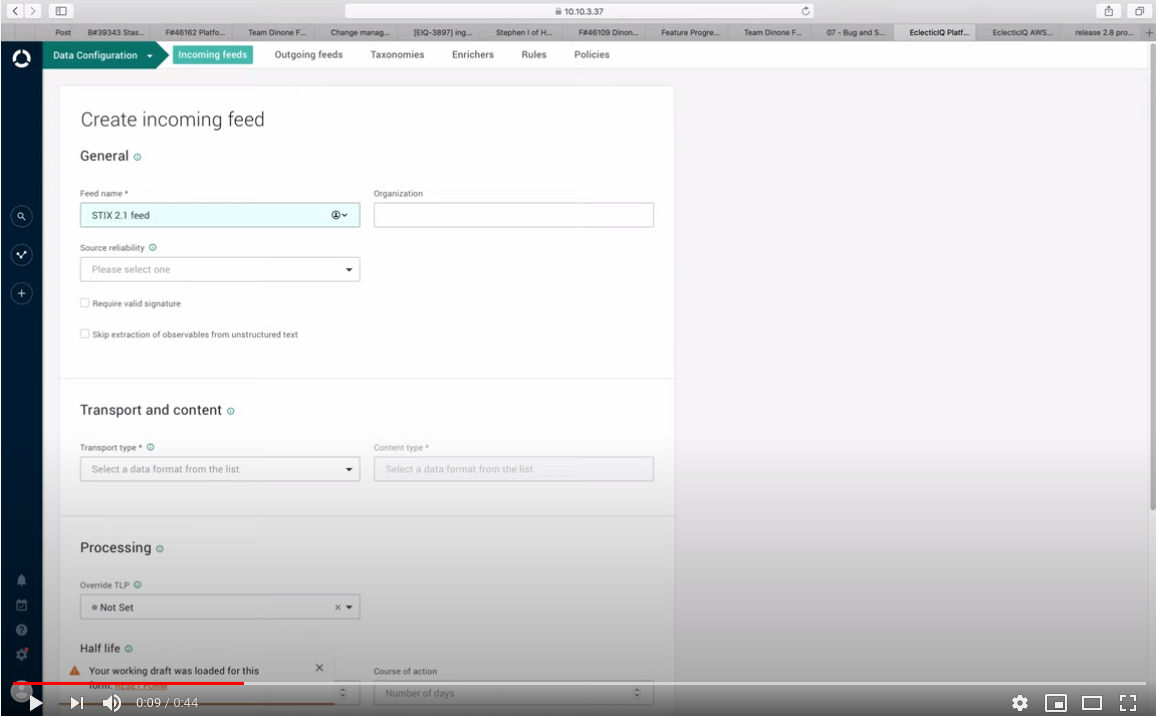
Search query validation
The new multiline editor helps analysts unravel the whole story a long and complex search query tells.
And search query validation highlights syntax errors by showing them in a different color.
Build search queries faster and fix any errors right away, before running the queries.
These features are now available in all search boxes across the platform, as well as in dataset and in rule creation forms.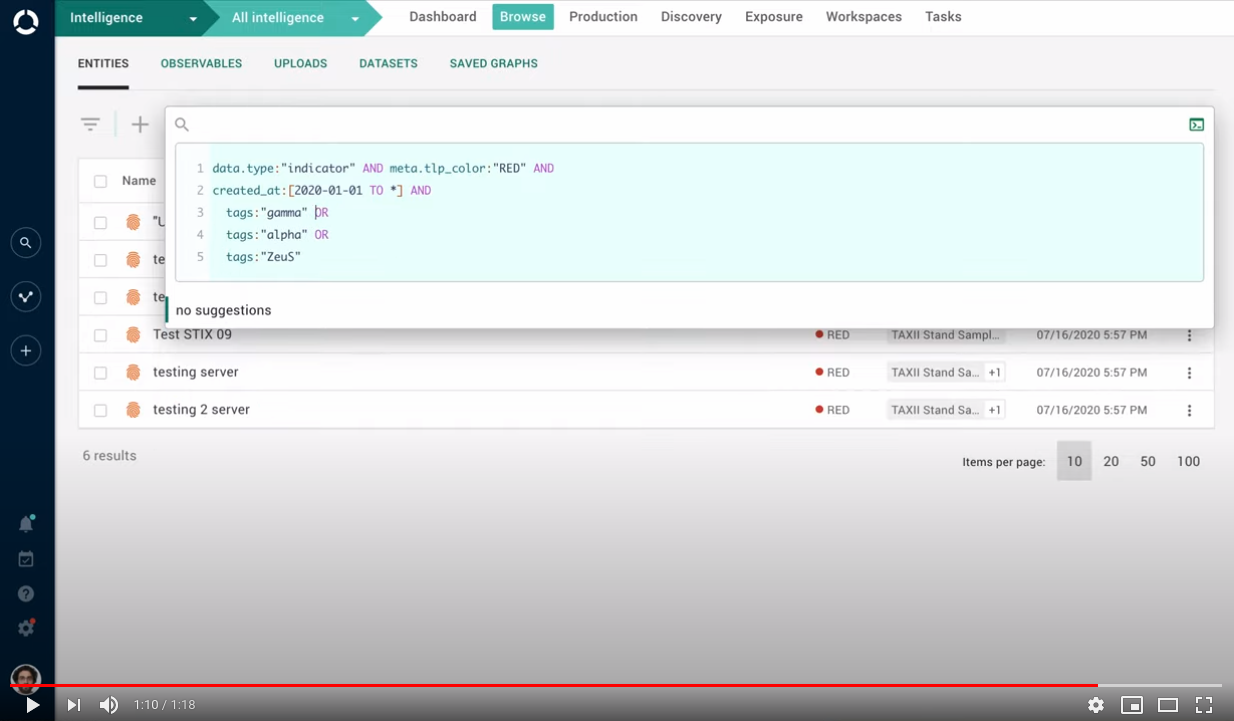
Intelligence creation: create a draft copy of a published entity
Sometimes you need to create entities that only differ slightly.
You can already create draft entities, and then duplicate them when you publish them. Now you can also create copies of already published entities.
This speeds up creating similar entities describing almost identical attack patterns or malware variants: create a prepopulated copy of an entity, and then edit only the information you need to change.
The duplicate entity is stored as a working draft, until you are ready to publish it to the platform.Intelligence creation: detect possible duplicates
When you manually create a new entity, how do you know if it already exists in the platform?
Before creating the new entity, you run a search in the platform. Or you do not worry about it, and you embrace the thrill that potential entity duplication gives you.
Save time, sweat, and manually fixing potential duplicates: when you create a new entity, the platform now tells you whether entities of the same type and with a similar name already exist.
So you can stop in time and waste no time.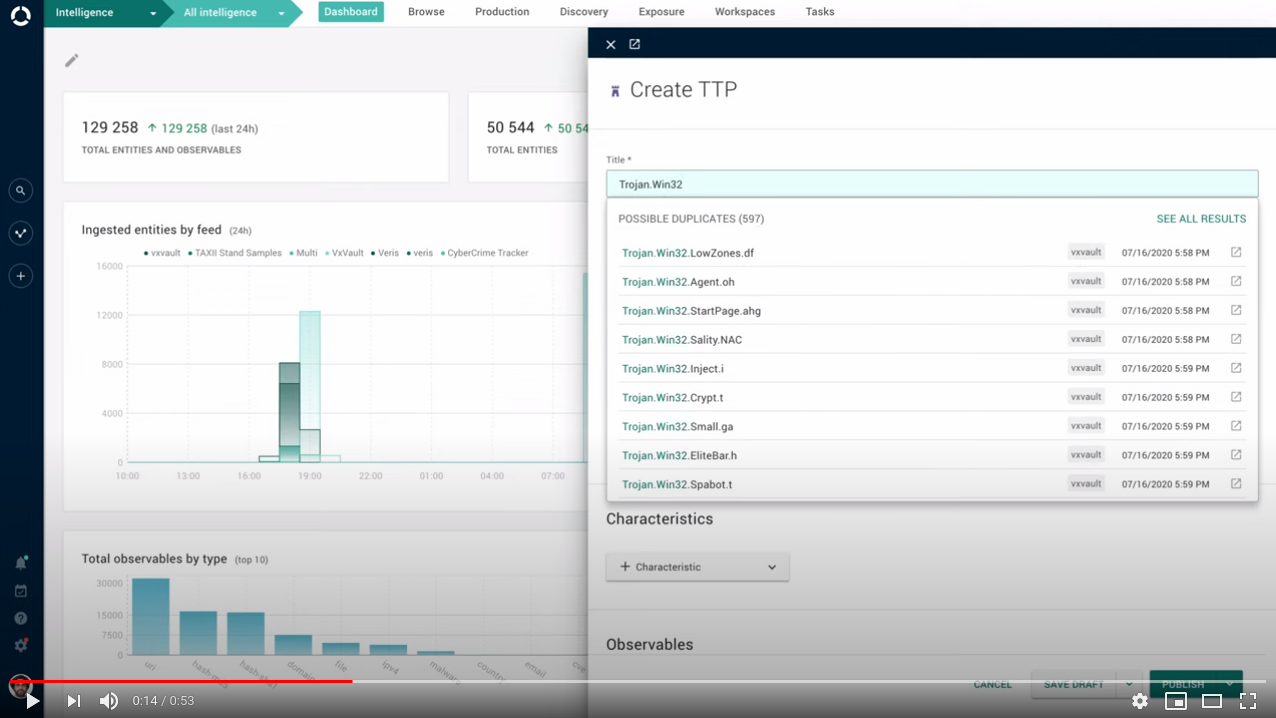
Intelligence creation: establish relationships in the graph
Relationships are important, in life as well as in the graph. Creating new relationships is easier and more intuitive: now you can do it right in the graph.
Select entities in the graph to create one-to-one and one-to-many relationships at once.
No need to worry about the direction of the relationships you are creating: the platform figures it out for you, based on the entity types you are connecting.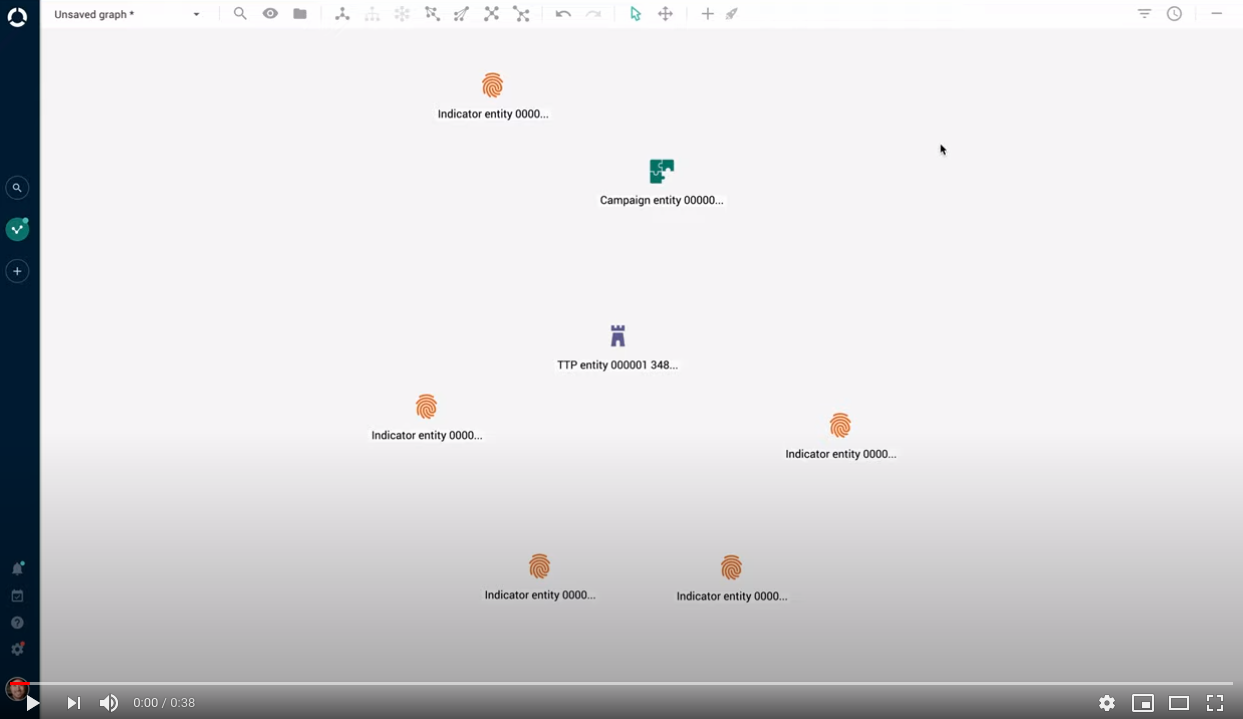
Datasets: new metrics tab
Less guesswork, better data.
The dataset detail pane now includes a new tab where you can review metrics information about the dataset, such as how it grows (number of ingested entities on a daily basis), and what type of intelligence it holds (entity count by entity type).
These are further categorized by entity type, confidence level, and date. You can also view a list of the dataset's entities filtered by taxonomy or tag.
This makes it easier to assess how active the dataset is, how fresh the data is, and how valuable.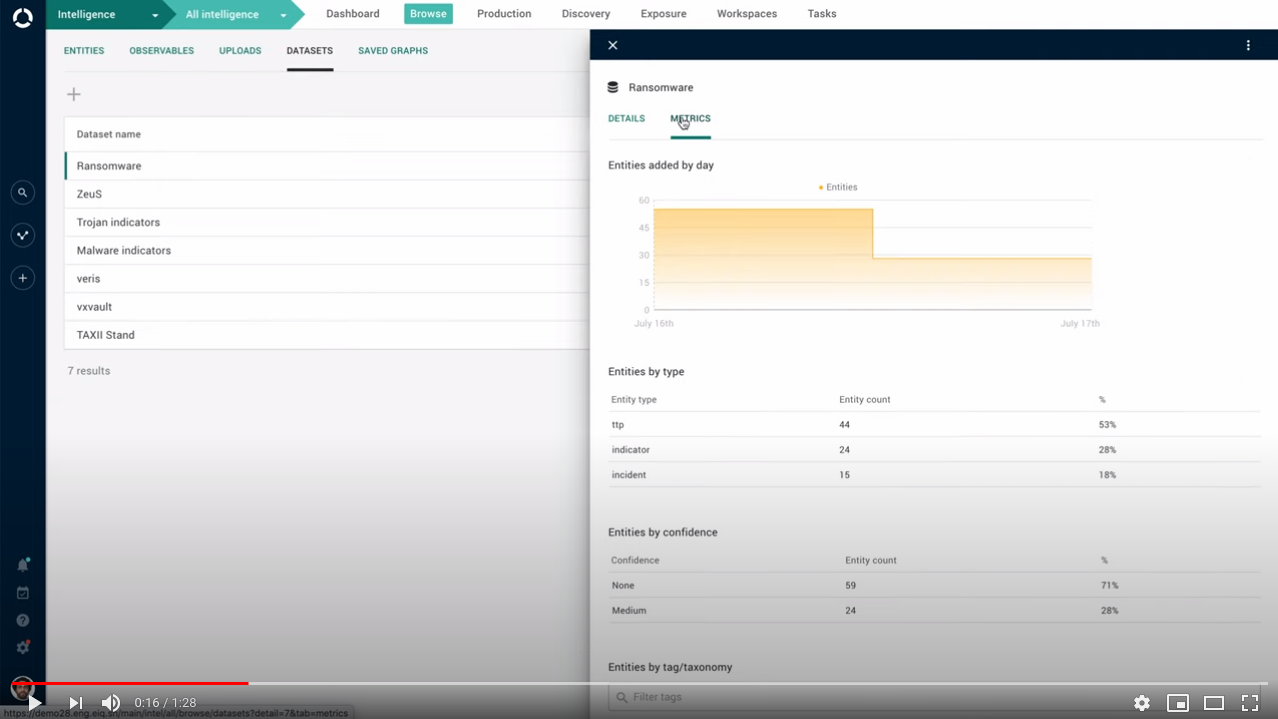
Elasticsearch: new diagnostics tool
A new diagnostics tool has been added to EclecticIQ Platform's arsenal. The new tool analyzes your Elasticsearch configuration and highlights possible areas for improvement.
In so doing it helps you plan your capacity as the amount of data you process in the platform grows.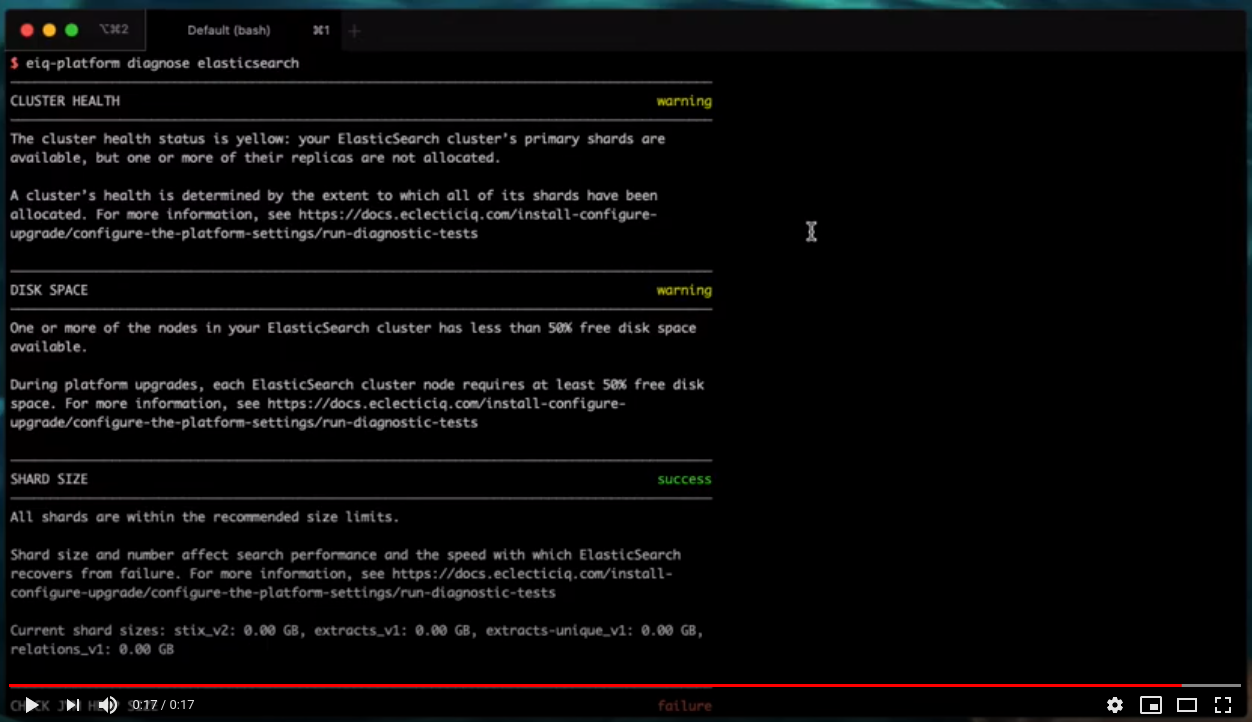
Reports: view attached PDF
This release improves PDF viewing in the platform.
Previously, it was possible to view a PDF attachment only when it was the source of a report entity. Now it is possible to view all PDF files attached to a report.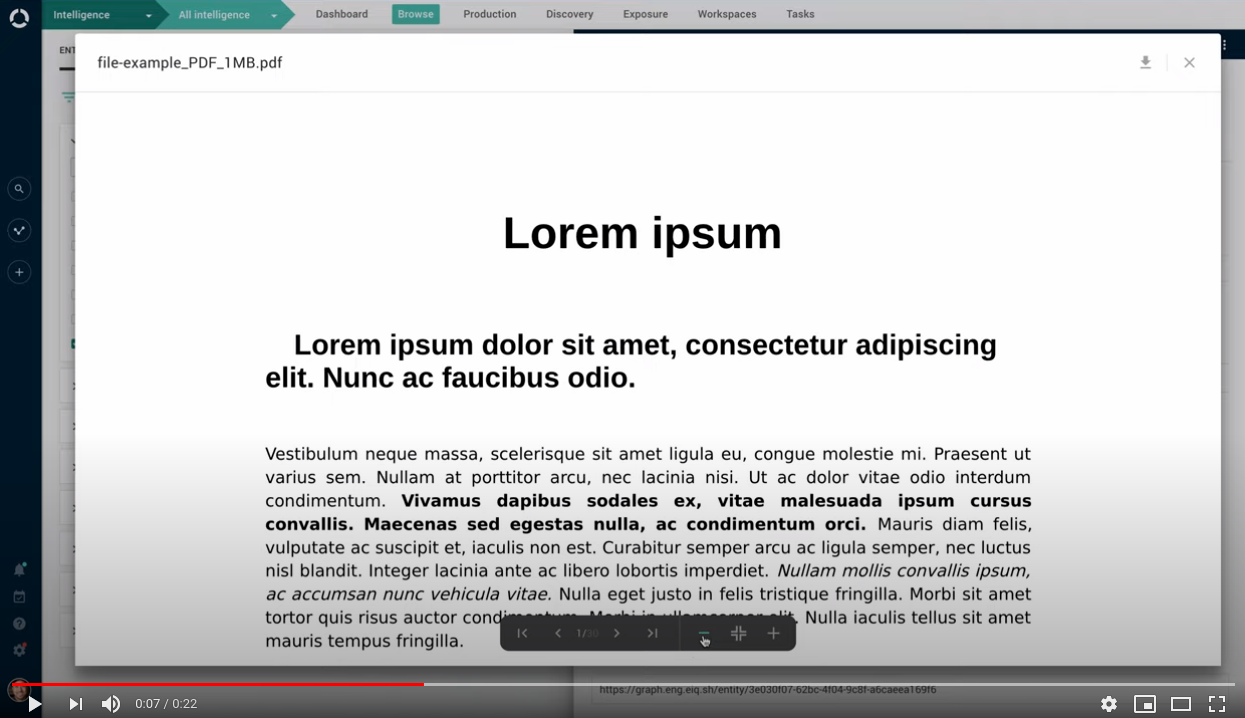
What's changed
Improvements
Ingestion: robustness and scalability
Data ingestion is more robust, more resilient, and faster.
Incoming feeds can pump into the platform large amounts of data without significantly affecting the performance of other running feeds.
The platform processes incoming data in smaller chunks to minimize the risk for bottlenecks.
It also optimizes system resource allocation to keep all running ingestion workers and all running incoming feeds efficiently busy.
This release includes a lot of under-the-hood work to improve the following areas:Data processing is more robust and more resilient throughout the ingestion pipeline.
Faster processing of highly connected datasets.
Depending on system resources, scaling up by increasing the number of active ingestion workers speeds up data processing.
Ingestion: URI authority check
URI extraction and normalization during data ingestion includes now an extra URI validation step. During URI normalization, the platform checks the URI for valid authority information such as user information, host name, ip address, and port.If the URI authority check succeeds, URI normalization continues, and the original URI is processed to be returned as a normalized URI.
If the URI authority check fails, URI normalization stops, and the original URI is returned as is.
Feeds: delete or purge incoming feeds
When removing an incoming feed from the platform, you get measurable feedback about the process until the job is completed.
The new feed purge progress dialog shows how many entities have been deleted from the platform, how many are queued up for deletion, and how far the process is, so that you can follow the deletion process in real time.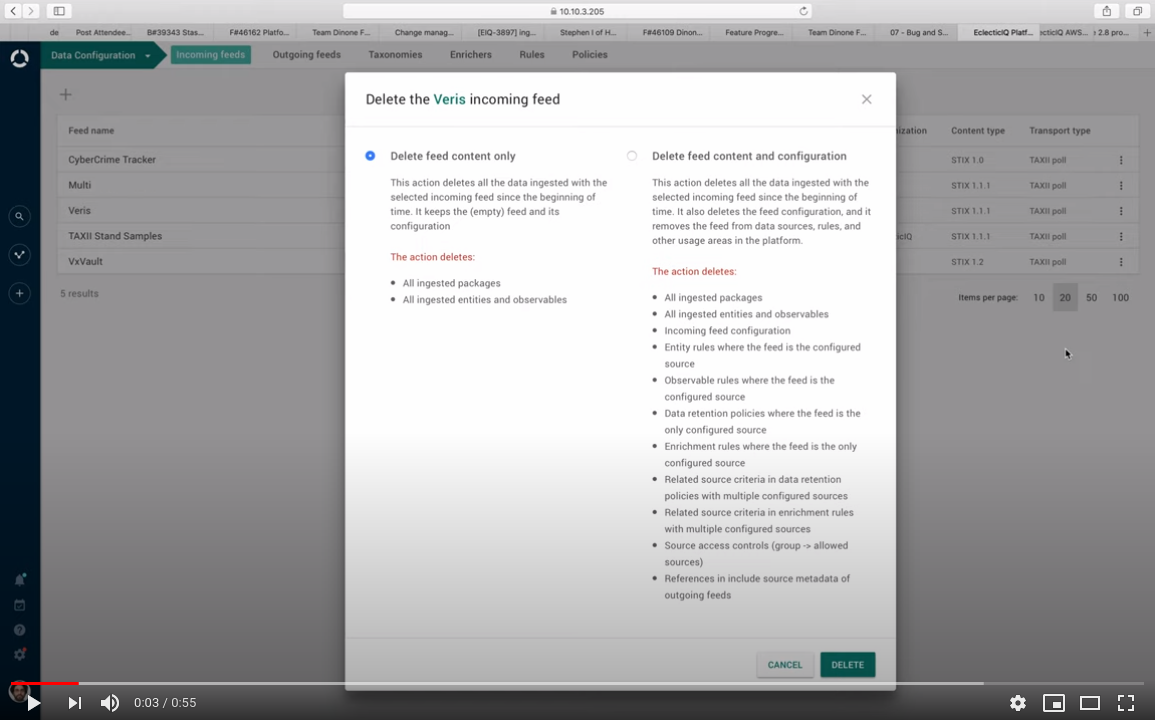
Feeds: select by taxonomy in outgoing feeds
Quickly select tags and taxonomies in outgoing feeds.
When you select taxonomy tags to include in the content published through an outgoing feed, select the parent taxonomy node to automatically include also the corresponding children.
Hover the mouse over the parent node to review the children.
Less clicking, more consistency, no accidentally missing child tags.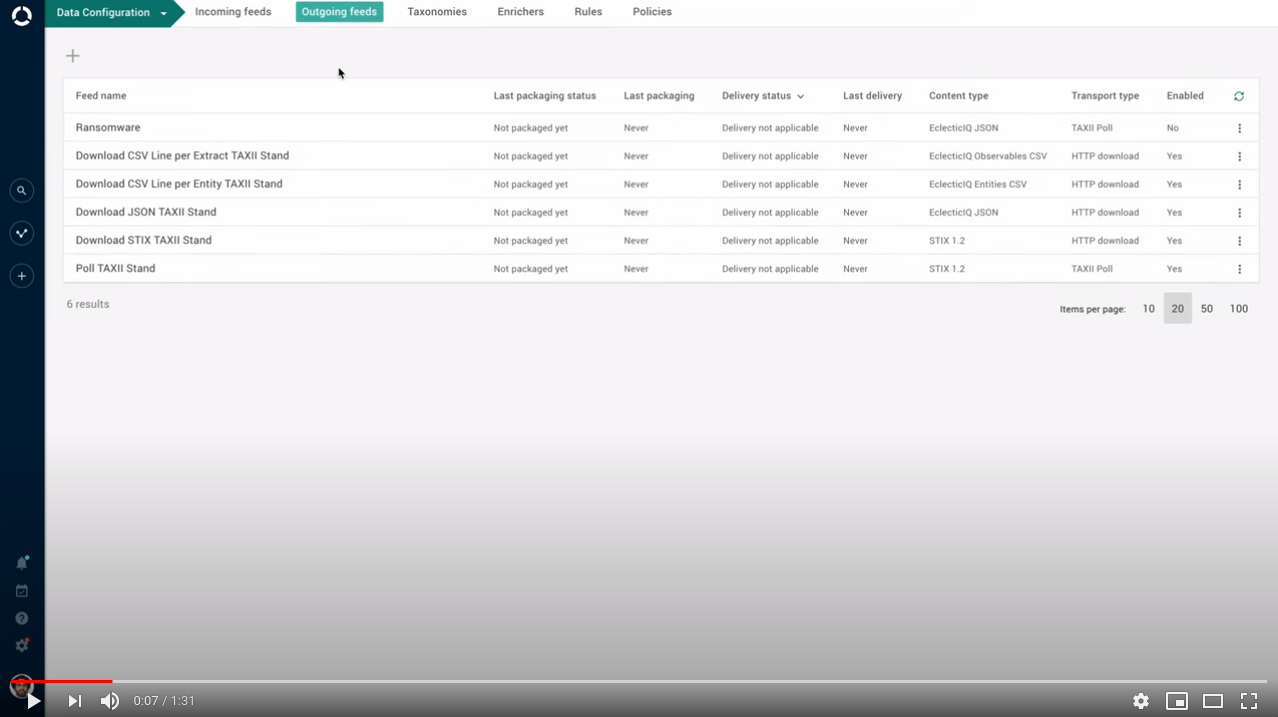
Logging: logs include only errors
As of release 2.8.0, the default logging level the platform sets for Elasticsearch, Neo4j, and PostgreSQL events is error, or an equivalent severity level for each of these products.A lower severity logging level such as info or warning can produce extensive log files for Elasticsearch, Neo4j, and PostgreSQL.
These log files can end up using considerable storage space, and they can be hard to navigate during a troubleshooting session because the data is noisy.A default logging level of error for Elasticsearch, Neo4j, and PostgreSQL logs provides clarity:
Log files are smaller in size.
Log files are easy to interpret: all logged event messages belong to the same severity level.
Logged events messages are actionable: an error state notifies that the affected component requires immediate assistance.
An error means that something failed, and it cannot resume normal operation.
You can change the logging level at any time to suit your requirements.
For more information, see how to set logging levels in CentOS, RHEL, and Ubuntu.
Important bug fixes
This section is not an exhaustive list of all the important bug fixes we shipped with this release.
Ingestion: Property value size too large to index into this particular index
During ingestion, incoming packages containing values exceeding 4036 bytes in size would fail to be ingested because the default Neo4j 3.5.x native-btree-1.0 index provider cannot process values larger than 4036 bytes.
The error traceback would include the following error message:Propertyvalue size: ${integer} of ${key value}istoo large to index into this particular index.Please see index documentationforlimitations.To ingest packages with key values larger than 4036 bytes, you need to enable support for larger key sizes by setting a different index provider for Neo4j 3.5.x.
An alternative index provider is lucene-1.0, whose key size limit is 32766 bytes.
EclecticIQ Platform 2.8.0 and later solve the issue by setting lucene-1.0 as the default index provider for Neo4j 3.5.x .To change native-btree-1.0 to lucene-1.0 as the default index provider for Neo4j in EclecticIQ Platform 2.7.x and earlier, you need to perform a manual procedure.
Entity editing: update does not produce a new version
We fixed a bug where editing a published entity in the detail pane, saving it as a draft, editing it again in the detail pane, and then publishing it would produce multiple copied of the entity, instead of only one.
It would no longer be possible to edit the original published entity, because it would be tied to a copy of the same entity in draft state.
Now editing an entity in the detail pane works as expected.
The detail pane retains the changes, and it updates the entity by producing a new version of the same entity.Observables: direct link to URI observable returns 404
We fixed a bug where clicking a direct URI link to an existing observable would return a 404 not found page, instead of correctly pointing to the existing observable, and loading the observable detail pane.
Now such URIs point to the resources they refer to, and the corresponding details load correctly in the GUI.Feeds: update timestamp issue while packaging content for an outgoing feed
We fixed a bug where the task that packages content for distribution through an outgoing feed would not pick up updated entities for repackaging to include the most recent changes.
The issue would occur when the last_updated_at timestamp of the updated entity was older than the last_updated_at timestamp of the running packaging task.
Now if an entity packaged for dissemination through an outgoing feed is modified while packaging the content of the outgoing feed, the packaging task correctly picks it up for repackaging to include the updated information, regardless of the entity last_updated_at timestamp being older than the last_updated_at timestamp of the running packaging task.History details
We fixed a bug where platform users with non-admin rights, and with the read history events permission could send GET API requests to specific API endpoints, whereby they could access history details related to workspaces, user tasks, entities, rules, and feed, regardless of their access level to those resources.
Now the API endpoints that expose history access perform stricter ACL verification also for the read history events permission.OpenTAXII: log files are not valid JSON
OpenTAXII produced log files (/var/log/eclecticiq/eiq-opentaxii.log) that were no longer correct JSON.
As a result, Logstash would no longer parse OpenTAXII messages as JSON, and it would tag them as jsonparsefailure.
This would make it more difficult to retrieve OpenTAXII log information in Kibana.
Now OpenTAXII produces valid JSON log files that Logstash correctly parses.
This makes it easier to retrieve OpenTAXII log information in Kibana, for example when troubleshooting.
Known issues
Search by relationship queries may time out when running a search such as "look for any entities that are related to this specific entity".
Example:?(data.type:"${entity type}")--("${UUID of a specific entity}")It is possible to create additional TAXII services in the platform. However, in the GUI it is not possible to delete created entries; users can only edit them.
As a workaround, it is possible to delete TAXII services by sending a DELETE request to the API endpoint exposing the TAXII service that is going to be removed:/private/collection-management-services/${TAXII service ID}
/private/discovery-services/${TAXII service ID}
/private/inbox-services/${TAXII service ID}
/private/poll-services/${TAXII service ID}
Ingested FireEye reports do not include the report also as a PDF attachment.
When exchanging data between two platform instances, and in case of sustained high throughput, the target platform instance may generate a queue of data waiting for ingestion.
When it starts processing the queue, the target platform instance does not ingest items in chronological order from oldest to most recent.When you configure the platform databases during a platform installation or upgrade procedure, you must specify passwords for the databases.
Choose passwords containing only alphanumeric characters (A-Z, a-z, 0-9).
Do not include non-alphanumeric or special characters in the password value.Systemd splits log lines exceeding 2048 characters into 2 or more lines.
As a result, log lines exceeding 2048 characters become invalid JSON.
Therefore, Logstash is unable to correctly parse them.When more than 1000 entities are loaded on the graph, it is not possible to load related entities and observables by right-clicking an entity on the graph, and then by selecting Load entities, Load observables, or Load entities by observable.
When creating groups in the graph, it is not possible to merge multiple groups to one.
In case of an ingestion process crash while ingestion is still ongoing, data is not synced to Elasticsearch.
Between consecutive outgoing feed tasks, the platform may increase resource usage. This may result in an excessive memory consumption over time.
Security issues and mitigation actions
The following table lists known security issues, their severity, and the corresponding mitigation actions.
The state of an issue indicates whether a bug is still open, or if it was fixed in this release.
For more information, see All security issues and mitigation actions for a complete and up-to-date overview of open and fixed security issues.
|
ID |
CVE |
Description |
Severity |
Status |
Affected versions |
|
ajv enables prototype pollution |
3 - HIGH |
|
2.8.0 and earlier. |
||
|
- |
Users with read-only permissions can delete objects from datasets |
1 - LOW |
|
2.7.1 and earlier. |
|
|
- |
Access to data sources through rules |
2 - MEDIUM |
Planned |
2.1.0 to 2.7.1 included. |
|
|
- |
Cross-site request forgery (CSRF) enables changes to Kibana |
1 - LOW |
Planned |
2.7.1 and earlier. |
Contact
For any questions, and to share your feedback about the documentation, contact us at [email protected] .